Living Semantic Web
Does the Semantic Web behave like a living system?
The goal of this work is to show how to model and analyse the Semantic Web as a whole, i.e. as a complex system.
To explain the difference between simple and complex systems, the terms “interconnected” or “interwoven” are somehow essential. Qualitatively, to understand the behaviour of a complex system, we must understand not only how the parts interact but also how they act together to form the behaviour of the whole. This is because we cannot describe the whole without describing each part, and because each part must be described in relation to other parts.
Complex Systems have demonstrated its power for modelling living systems, such as neural networks or food webs, and technologicalnetworks, such as Peer-to-Peer systems, Multi-Agent Collaboration networks, the World Wide Web or power grids, using statistical mechanics.
The question is: could the Semantic Web be modelled as a living system, which is a subclass of Complex Systems? The answer is yes, if we consider that both systems present the same regularities (predictable, mechanistic laws) and dynamics (self-organization, adaptation or evolution).
We have modelled a meaningful portion of the Semantic Web showing that it satisfies Complex Systems properties. First, as detailed in the next sections, we have “crawled” a set of ontologies building the RDF graph model that they define. Second, we have applied statistical tools to extract graph properties in order to compare to other complex systems. Finally, we report experimental values.
1. Semantic Web graph
The first step towards analysing the Semantic Web as a Complex System is to build an appropriate graph model. Due to self-similarity of complex systems, we have selected a significant portion of the Semantic Web to perform the study. It comprises the ontologies available from the DAML Ontology Library.
A modification of the RDFCrawler using the Jena RDF parser (New RDFCrawler, available from the bottom of this page) was launched over all the DAML Library ontology URIs and all the others that were referenced from them, for instance RDF Schema or DAML+OIL. Some of them were unavailable and others not processable by Jena. The 196 processed URIs were combined in a RDF graph and serialised in N-Triples form. The RDF graph was the result of combining 160,000 triples and the starting point of the study:
- New RDFCrawler → DAML Ontology Library (processed URIs, crawler log) → RDF graph (N-Triples serialisation)
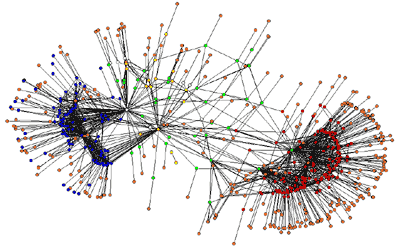
The same has been applied to a smaller portion of the Semantic Web, starting from an individual ontology, CopyrightOnto, and the ontologies referenced from it. CopyrightOnto is an copyright ontology we have developed. This parallel analysis will allow comparing different scales results. The graph for CopyrightOnto is much smaller, only 971 nodes, and it is shown in Fig. 1.
 |
|
Fig. 1. Graph model for CopyrightOnto ontology and the schemas referenced from it, directly or indirectly. Red nodes correspond to IPROnto concepts, blue ones come from different Dublin Core schemas and, on the center, a combination of resources from RDF/S (white/yellow) and OWL (light green). Finally, literals and anonymous resources are the orange nodes
|
2. Graph Analysis
In order to analyse the Semantic Web graph we obtained, Pajek, a large networks analysis tool, was selected. The RDF N-Triples serialisation was translated to a ‘.net’ Pajek network file. The triples subjects and objects became network nodes connected by directed edges from subject to object. Nodes are identified by their original URIs to allow network construction and the edges are unnamed so duplicated edges are ignored. This is so because we do not need all this information. We are only interested in the network structure.
The Pajek network has 56,592 nodes and 131,130 arcs. Once loaded in Pajek, the available tools were used to obtain the required information about the graph:
- Average degree and degree distribution: using the Net/Partitions/Degree command.
- Clustering factor: using the Net/Vector/ClusteringCoefficients command.
- Average minimum path length: average over a random selection of 20 nodes (using Partition/CreateRandomPartitions and Partition/MakeCluster of size 20) and the averages of their k-neighbours vectors (using the Net/k-Neighbours with the Net/k-Neighbours/FromCluster option).
- Power-law tails exponent: linear regression from the degree distribution using GNUPlot.
3. Results
The numeric results of the graph analysis are shown in Table 1. The two lines show the analysis of the network of ontologies at the DAML Ontologies Library in two different time points. This time distant measures will allow to show if the complex system nature of the Semantic Web is independent from time. The third one shows the same measures for the Copyright Ontology. This will allow to show if the Semantic Web is a complex system at different scales. All this measures can be compared with those from other complex systems networks: the results from WWW studies and human language words network.
Table 1. This table shows the compared networks, their number of nodes, the average degree , clustering factor C, average minimum path length and power-law tails exponents g
| Network |
Nodes |
k |
C |
d |
g |
DAMLOntos
(2003-4-11) |
56592 |
4.63 |
0.152 |
4.37 |
-1.48 |
DAMLOntos
(2005-1-31) |
307,231 |
3.83 |
0.092 |
5.07 |
-1.19 |
| CopyrightOnto |
971 |
3.71 |
0.071 |
3.99 |
-3.29 |
| WWW |
~200 M |
- |
0.108 |
3.10 |
-2.10 |
| WordsNetwork |
500000 |
- |
0.687 |
2.63 |
-1.50 |
From the previous data we can deduce that the Semantic Web is an Small World comparing its graph to the corresponding random graph, with the same size and average degree. The clustering factors C = 0.152 and C = 0.092 are much greater than that for the corresponding random graph Crand = 0.0000895, while the average path lengths d = 4.37 and d = 5.07 are similar to that for the corresponding random graph drand = 7.23. For CopyrightOnto the same holds, Crand = 0.0034272 and drand = 5.38.
On the other hand, studying the degree distributions, their scale-free nature has been detected and the power-law exponents have been calculated.
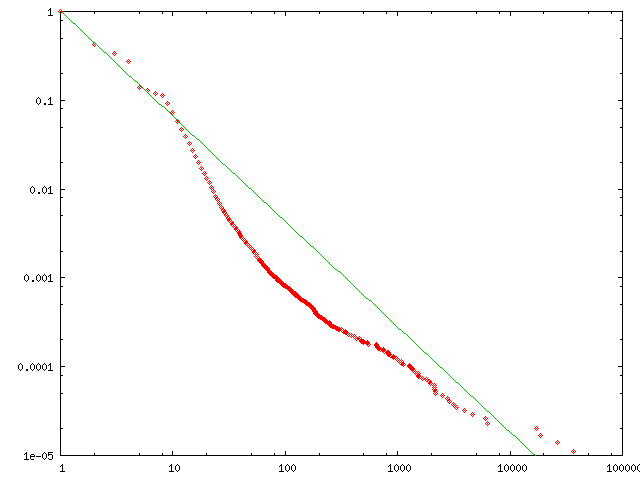
The final evidence is the degree distribution; it is clearly a power-law. The degree Cumulative Distribution Function (CDF) for the older DAMLOntos has linear regression with an exponent g = -1.485 with a regression error e% = 1.455. In the last study of DAMLOntos, the linear regression of this function gives an exponent g = -1.186 with a regression error e% = 0.896. The linear regression plot is shown in Figure 2.
 |
|
Fig. 2. Logscale degree distribution for the set of studied DAML library ontologies DAMLOntos) plus linear regressions and computed exponents for the two differentiated regions
|
Therefore, the graph for the portion of the Semantic Web that has been analysed shows clear evidences that the Semantic Web behaves like a Complex System. It is a small world, with a high clustering factor and a power-law degree distribution. It has also a scale-free nature, so the same properties can be observed at a different scale. In fact, as the measures shows, this is the case for different time points and differents scales. To conclude, we can deduce that the Semantic Web behaves like a Complex System and, consequently, we can say that it is one of them.
More detailed results are available from the following publications.
Publications
Measuring the Semantic Web v2 

Gil, R. and García, R.
First on-Line conference on Metadata and Semantics Research, MTSR 2005
Rinton Press, 2006
Measuring the Semantic Web v1
Gil, R., García, R. and Delgado, J.
"Semantic Web Challenges for Knowledge Management: towards the Knowledge Web",
SIGSEMIS Bulletin Vol 1, Issue 2, pp 69 - 72. July 2004
Towards the Composition of Ad Hoc B2B Applications
Gil, R., Choukair, Z. and Delgado, J.
Workshop on Application Design, Development and Implementation Issues in the Semantic Web,
World Wide Web Conference WWW'04, 2004
New RDFCrawler
The New RDFCrawler is a modification of the existing RDFCrawler. The RDF API has been updated to Jena in order to cope with the great amout of RDF metadata available in the Web. Moreover, some other changes have been introduce to improve its capabilities. They are summarised in the next points:
- Memory management: the new version does not use exclusively an "in-memory" approach. Once an URL with RDF metadata has been loaded and parsed, it is serialised to a common file in N-Triples form. Therefore, once serialised, memory can be freed and the process is iteratively applied builing the global RDF model in the disk file. This allows crawling much bigger RDF models.
- DAML Ontology Library: it has been extended an now is able to extract the starting URLs from an HTML file containing a list of them, for instance the DAML Ontology Library.
- RDF to Pajek Net translator: there is a separated translator from input RDF models, serialised in RDF/XML or N-Triples form, to Pajek nets in ".net" format. From RDF triples, subjects and objects become network nodes connected by directed edges from subject to object.
Installation
Download an unzip LivingSW.zip. It contains the source code (/src), compiled code (/bin), a regular expressions package (/lib) and a pair of useful scripts. Moreover, the New RDFCrawler requires some libraries from Jena to be placed at /lib. It has been tested with those from the Jena 1.6.1 version: jena.jar, icu4j.jar, xerces.jar, junit.jar, concurrent-1.3.0.jar
Use
The different functionalities of the New RDFCrawler are packed in the two provided scripts. The first one launches the crawler. There are two options, the first one crawls from URL for the given time and crawling depth. The second, pre-processes the given HTML URL to extract the URL from which the crawling will be performed.
> rdfcrawl URL [depth :int] [time :int]
> rdfcrawl base :htmlURL [depth :int] [time :int]
The other script is used to convert the N-Triples RDF model produced by the crawler to a Pajek Net. Moreover, It can alco convert RDF/XML input serialisations files:
> nt2pajek rdfserialisationfile(.nt|.xml)