UDDI Services
The intention of this section is not to make a complete state of the art of web technologies. The purpose of this memory is to recompile the research work related to Semantic Web and its perspectives. Therefore, the focus of this section is on presenting current web technologies and the actual web scenario. They will be used as the building blocks and the starting point from where to explore the development of new solutions. The premise is that the Web can be completed with the contributions of a new proposal that may solve some of its problems, the Semantic Web.
The World Wide Web appeared as the result of the need to integrated many disparate information systems. The approach was to form an abstract space in which the differences between them did not exist. The Web had to include all information of any sort on any system.
Back in 1989, when the World Wide Web was first conceived, many different information systems existed. They ran on different sorts of computers, each running different operating systems, connected by different networks, and using quite different programs to give to the user very different ways of accessing information. Thus, while the information on two systems might be very relevant, the path between them was very long.
In fact, the Internet already existed. Each of the computer systems was very likely to be connected to some sort of network, which very likely was in turn connected to another network. There was a path from a bit of data on one computer through a series of networks to the other computer. Thus, there was no reason why software and hardware barriers to communication should exist. Software and device independence was achieved in both sides, the client accessing information and the server offering it.
The Web started to be deployed with only a common idea needed to tie it all together, the URI (Universal Resource Identifier) that identified a document in the WWW abstract space. From that cascaded a series of protocols, such as HTTP (HyperText Transport Protocol), and data formats, such as HTML (HyperText Markup Language), which allowed computers to exchange information, mapping their own local formats into standards that provided global interoperability.
The abstract space of the World Wide Web is based on the distributed hypermedia paradigm that is the synthesis of three ideas [Heylighen94]:
The World Wide Web is now established as a unified interface to the Internet computer network. This universal acceptance is due to the Web is extremely simple, but a powerful way of representing networked information. Its simplicity comes from the premise of providing the maximum freedom to its users. It is resumed in the principle anyone can say anything about anything in the WWW.
For instance, this can lead to links that point to non-existent documents. This kind of situations was initially seen as inappropriate in an information system. However, this lack of strong constraints has turned to be the Web's most important reason for its success.
From the previous introduction, a set of Web building blocks can be extracted. They conform a quite simple basis over which the whole World Wide Web has evolved.
They play in the Web more or less the same role than IP (Internet Protocol) addresses in the Internet. An IP identifies a device in the global framework of the Internet; an URI is a global document identifier [Berners-Lee98].
Due to the original uses of URI in the starting Web, URI as best known for the subset called URL (Universal Resource Locator). This subset is intended for resource location, i.e. how to reach a document. On the other hand, the other subset of URI, URN (Universal Resource Name), is exclusively used for resource identification. Thus, URI is the generic term for both, resource location and/or identification in the World Wide Web.
For examples URIs include,
It is the WWW communications protocol. HTTP defines how to carry on conversations between Web clients and servers in order to move data across the Web. HTTP is a simple stateless protocol reduced to the interchange of request and response messages between the client and the server [Fielding99]:
World Wide Web documents have this data format. This format defines how to pack into web documents textual information, external multimedia resources and interactive links to other web documents. Therefore, HTML provides the first two features of the Web presented in the previous section, hypertext and multimedia.
Like the Web, its data format has also suffered rapid evolution that has eventually carried it to confusing situations where a unified standard was not clear. Recently, a normalisation effort has been completed and the XHTML standard [Pemberton02] has been produced. It updates HTML using more recent web technologies that connect it to the initiatives presented in the Recent Developments section.
As was presented in the introduction, the World Wide Web has had an enormous success. The result is that the Web has grown exponentially and it currently has acquired enormous proportions.
This is a good new for its users; there is an immense amount of information and opportunities in the WWW to exploit. However, simple accumulation is not the response. In order to efficiently exploit it and extract its full potential more elaborated mechanisms should be layered over the basic building blocks that the Web provides.
Before entering in an overview of some of the currently proposed mechanisms, some examples of the problems the World Wide Web is encountering are presented. They are introduced through a series of scenarios that illustrate real cases of these problems. These scenarios have been selected because they are relevant, they seem to be explanatory and they have been found and even faced during the research work summarised in this work.
The great success has been combined with an increasing need of mobility and ubiquity. That is the reason why lastly highly portable devices with web access capabilities have appeared.
This kind of devices has special constraints that do not allow transparent access to the Web as it is now. For instance, size limitations reduce device computation capabilities, screen sizes and available peripherals.
This puts back to focus a previously observed problem that seemed to have been solved. There is not clear separation between content and presentation in the web data format. This was seen during the “browsers” war, more and more features were introduced in the main web clients that required proprietary add-ons to HTML. Very specific features bound the transmitted content and the actual presentation they acquired in the intended browser.
The browsers' problem was more or less resolved, though still now web documents must include specialised commands to tailor their content to the accessing browser. There was possible some consensus but principally it was resolved by “brute force”, one of the contestants practically became a de-facto standard.
The current situation is more complicated. The range of clients is greater and differences between them cannot be resolved in practice with ad-hoc methods. Some devices even use HTML inspired data formats that are not compatible, like WML (Wireless Mark-up Language).
Now, a clear effort to separate content and presentation has been initiated and, indeed, many results are yet available. Some technologies that at least try to solve this problem are commented in the Recent Developments section.
The amount of information in the World Wide Web is enormous and it makes complicated that users find what they are looking for. A great effort is necessary to locate relevant results among the many times not very accurate outputs of web search engines.
Search engines rely on mainly syntactic means for content matching with user queries. Matching is based on direct comparison of query keywords and the worlds that appear in web documents.
Due to natural language words ambiguity, due to properties like synonymy or polysemy, syntactic methods are not very accurate. Full processing of natural language is currently not available so, in order to automate high quality content location, other approaches should be considered.
The best option is to carry on some kind of pre-processing of web documents. This pre-processing can be performed with machine support, but human intervention is currently mandatory if reliable results are required. Pre-processing produces metadata. It is data about data, in this case some relevant keywords about a web document. They are associated to web documents so a search engine can retrieve them in order to focus matching, in theory they are selected as the world that best represent documents content.
However, this approach does not solve the ambiguity problem. Both, the keywords from the queries and those from web documents metadata can be ambiguous. A recent attempt to solve that uses mechanisms that allow annotators and requesters to relate the keywords they use. These relations state equivalence, broader or narrower terms, etc. between keywords. Following them, many ambiguities can be overcome. This approach is part of the Semantic Web initiative and is detailed in the Semantic Web section.
This is an augmented version of the search engines scenario. In this scenario, not only content location is involved. The Web is evolving to become more than a collection of information. This is a particularly sensitive issue in the business world, which is trying to exploit the Web's full potential.
The augmented web is conformed from what are called web services. They make possible business-to-business interactions through the web. However, thought the business world is being the driving force of the Web Services initiative, the whole web and the full range of its uses can be benefited. More details are presented in the Web Services section.
This is a subset of the business scenario. It concentrates on trading copyrighted content in the Web. The objective is to have automated content rights negotiation and mechanism that help to guarantee their fair use.
This rather specific scenario has been highlighted because many of the results presented in this research memory belong to this scenario.
Extensible Mark-up Language [Yergeau04] is not an alternative to HTML. They complement themselves as they have different objectives; indeed XML appeared to deal with some features that HTML does not cover. XML is a meta-language for creating mark-up languages to describe data. In contrast to HTML, which describes document structure and visual presentation, XML describes data in a human readable format with no indication of how the data is to be displayed. It centres its attention on content.
Therefore, with XML, content and presentation are effectively separated. It is a database-neutral and device-neutral format. Data marked up in XML can be targeted to different devices using eXtensible Style Language [Adler01]. XSL style sheets connect XML content to their presentations. They conform a template that translates selected XML portions to their output format. Usually, HTML is the output format but there is not restriction on what can be produced. For instance, there are style sheets to produce Acrobat® Portable Document Format or WML documents.
Since XML is truly extensible, rather than a fixed set of elements like HTML, use of XML will eventually eliminate the need for browser developers and middleware tools to add special HTML tags, i.e. extensions.
This is possible because XML is a meta-language used to define other domain or industry-specific languages. To construct a specific XML language, also called a vocabulary, a Document Type Definition is defined. A DTD is essentially a context-free grammar. In other words, a DTD provides the rules that define the elements and structure of the new language. An examples of a DTD is presented in Table and some XML of the language defined by this DTD is shown in Table.
DTD for and Address book XML language
| <?xml version="1.0" encoding="UTF-8"?> <!ELEMENT ADDRESSBOOK (PERSON)*> <!ELEMENT PERSON (LASTNAME, FIRSTNAME, COMPANY, EMAIL)> <!ELEMENT LASTNAME (#PCDATA)> <!ELEMENT FIRSTNAME (#PCDATA)> <!ELEMENT COMPANY (#PCDATA)> <!ELEMENT EMAIL (#PCDATA)> |
XML document containing example data for the Address book XML language in Table
| <?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE ADDRESSBOOK SYSTEM "addressbook.dtd"> <ADDRESSBOOK> <PERSON> <LASTNAME>Baggins</LASTNAME> <FIRSTNAME>Frodo</FIRSTNAME> <COMPANY>The Fellowship of the Ring</COMPANY> <EMAIL>frodo@baggings.com</EMAIL> </PERSON> <PERSON> <LASTNAME>Gamgee</LASTNAME> <FIRSTNAME>Samwise</FIRSTNAME> <COMPANY>The Fellowship of the Ring</COMPANY> <EMAIL>sam@ringfellowship.org</EMAIL> </PERSON> </ADDRESSBOOK> |
Another way of defining XML languages is using XML schemas. XMLSchema [Fallside01] is an evolution of DTD that provides more sophisticated constructs that allow defining XML languages with richer structure and less effort.
The current web is mainly a collection of information but does not yet provide support in processing this information, i.e., in using the computer as a computational device. Recent efforts around UDDI, WSDL, and SOAP, all detailed next, try to lift the web to a new level of service. Software programs can be accessed and executed via the web based on the idea of web services. A service can provide information, e.g. a weather forecast service, or it may have an effect in the real world, e.g. an online flight booking service. Web services, opposite to web browsing, change things. They are remote operations with side effects.
The web is organized around URI, HTML, and HTTP as has been shown in the Building blocks section. Not surprisingly, web services require a similar infrastructure around three analogous technologies: UDDI, WSDL, and SOAP [Fensel02].
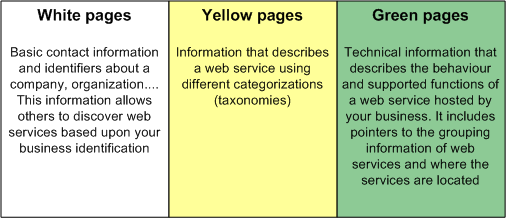
Universal Description Discovery and Integration [Bellwood02] provides a mechanism for clients to find web services. Using a UDDI interface, clients can dynamically lookup as well as discover services offered by web service providers.
A UDDI registry has two kinds of clients. Firstly, users that want to publish service descriptions and its usage interfaces. Secondly, users who want to obtain services descriptions of a certain kind and bind programmatically to them using SOAP.
UDDI itself is layered over SOAP and assumes that requests and responses are UDDI objects sent around as SOAP messages.
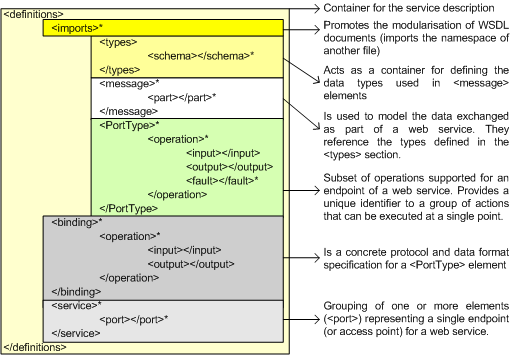
Web Services Description Language [Chinnici02] defines services as collections of network endpoints or ports. In WSDL the abstract definition of endpoints and messages is separated from their concrete network deployment or data format bindings. This allows the reuse of abstract definitions of messages, which are abstract descriptions of the data being exchanged, and port types, which are abstract collections of operations.
The concrete protocol and data format specifications for a particular port type constitute a binding. A port is defined by associating a network address with a binding; a collection of ports defines a service.
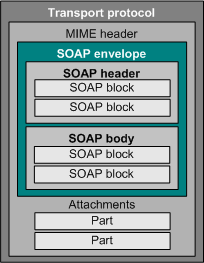
Simple Object Access Protocol [Mitra02] is a message layout specification that defines a uniform way of passing XML-encoded data. It also defines a way to bind to HTTP as the underlying communication protocol, although other communication protocols can be used, for instance electronic mail.
Instead of being document-based, automated B2B interaction requires integration of processes. However, although techniques such as DCOM, RMI and CORBA are successful on the local network, they largely fail when transposed to a web environment. They are rather unwieldy, entail too tight a coupling between components and above all conflict with existing firewall technology.
Replacing this by a simple, lightweight mechanism similar to Remote Procedure Call is the aim of SOAP. Hence SOAP is basically a technology to allow for "Remote Procedure Calls over the web" providing a very simple one-way as well as request and reply mechanism.