ODRL XML complexTypes formalised as OWL classes' hierarchies
This evaluation chapter has been conceived as the place to show all that has been done in order to put the contribution of this work into practice and validate it. The more direct way of evaluating the contribution is using ontology evaluation tools like the ones provided by some ontology editors or reasoners. This kind of evaluation has been performed during the ontology formalisation phase, which has not been documented in this work as it has been automatically performed by the ontology modelling tools that have been employed.
There are also indirect ways of evaluating it. The approach that has been taken for this is to take profit from the XML Semantics Reuse methodology in order to generate ontologies for the main rights expression languages that are based on XML Schemas: MPEG-21 REL and ODRL.
The same has been done for MPEG-21 RDD, which is not an XML Schema but a ontology. However, it is not defined using a formal ontology language. Therefore, a method to map it to a web ontology has been also developed and it has produced also a formal ontology for the RDD.
Once all this initiatives are available as web ontologies, it has been possible to put the Semantic Web approach into practice with them. The benefits of moving them to the Semantic Web are shown. Therefore, there is an additional contribution independent from the main contribution, i.e. the Copyright Ontology. It is to apply the Semantic Web to other REL initiatives.
Moreover, another consequence of moving all this initiatives to web ontologies is to facilitate validating the Copyright Ontology. Once they are also in OWL form, it is easy to try to map them to the Copyright Ontology. It can be then checked if all the concepts in this ontologies have an anchor point in the Copyright Ontology where they can be mapped.
Although all the previous initiatives have been mapped to web ontologies and used to implement semantics-enabled applications that show the Semantic Web approach benefits, their mappings to the Copyright Ontology have not been completed.
Then, it remains future work to do an extensive evaluation of the Copyright Ontology in relation to other REL initiatives. However, to the extent that this mapping has been already implemented, it can be concluded that the Copyright Ontology provides a base framework where this initiatives can be plugged-in using Semantic Web tools based on ontology primitives for concept inclusion and equivalence and Semantic Web rules.
Finally, the Copyright Ontology has been put into practice in the context of a semantics-enabled DRM system called NewMARS. This system has been developed using a knowledge-oriented approach. The more important part of the system is the knowledge layer, which is composed by the Copyright Ontology and other multimedia description ontologies.
On top of this ontologies layer, the whole system has been implemented based on semantic metadata. Semantic metadata is present from storage access, which is performed by semantic queries, through retrieval and metadata integration, which is done based on RDF graphs, to metadata rendering and user interaction, which is based on HTML rendering of RDF metadata and semantics-enabled HTML forms.
In order to move Digital Rights Management to the Internet, a common rights expression language is needed. ODRL (Open Digital Rights Language) is one of the proposed solutions. It is based on a XML language and thus it just formalises the language syntax, while language semantics are specified informally.
Actually, ODRL seems quite complete and generic enough to cope with such a complex domain. However, the problem is that it has such a rich structure that it is difficult to implement. In our opinion, it lacks formal semantics that would help ODRL applications development.
As the application context is the Web, the approach to formalise ODRL semantics is based on semantic web ontologies. Firstly, ORDL has been moved to the Semantic Web space using XML Schema to OWL and XML to RDF tools detailed in the XML Semantics Reuse section. This provides some simple semantics.
In order to refine them, the resulting ODRL ontologies have been connected to the copyright ontology described in the contribution part of this work. The interrelation of the copyright ontology with the ontologies resulting from the XML Schema to OWL mapping enables semantics-aware ODRL applications that benefit from semantic queries.
This contrasts with the difficulties that emerge from the use of syntactic queries when the information space is as complicated as in the DRM field. Moreover, specialised reasoners can be used for license checking and retrieval. All these advantages have been propagated to ODRL thanks to this mapping.
The amount of digital content delivery in the Internet has made Web-scale Digital Rights Management (DRM) a key issue. Traditionally, DRM Systems (DRMS) have deal with this problem for bounded domains. However, when scaled to the Web, DRMSs are very difficult to develop and maintain. The solution is interoperability of DRMS, i.e. a common framework for understanding that defines a shared rights expression languages and its associated vocabulary.
ODRL (Open Digital Rights Language) [Iannella02] is one possible approach to that. As it has been detailed in the State of the Art ODRL section, it is a XML language defined by two XML Schemas. The first XML Schema, called EX-11, defines the language syntax and a basic vocabulary. The second XML schema is called DD-11 and it contains the data dictionary. It provides the complete vocabulary with textual definitions and a lightweight formalisation of the vocabulary terms semantics as an XML Schema.
ODRL seems quite complete and generic enough to cope with such a complex domain. However, the problem is that it has such a rich structure that it is difficult to implement. It is rich in the context of XML languages and the "traditional" XML tools like DOM or XPath. There are too many attributes, elements and complexTypes to deal with, as it is shown in Table.
Number of named XML Schema primitives in ODRL
|
|
ODRL |
|
|
Schema |
EX-11 |
DD-11 |
|
xsd:attribute |
10 |
3 |
|
xsd:complexType |
15 |
2 |
|
xsd:element |
23 |
74 |
|
Total |
127 |
|
For instance, consider looking for all constraints in a right expression that apply to how we can access the licensed content. This would require so many XPATH queries as there are different ways to express constraints. ODRL defines 23 constraints: industry, interval, memory, network, printer, purpose, quality... This amounts to lots of source code, difficult to develop and maintain because it is very sensible to minor changes to the ODRL specification. Fortunately, there is a workaround hidden in the language definitions.
As we have said, there is the language syntax but also some semantics. The substitutionGroup relations among elements and the extension/restriction base ones among complexTypes encode generalisation hierarchies that carry some lightweight taxonomy-like semantics. For instance, all constraints in ODRL are defined as XML elements substituting the "o-ex:constraintElement". The difficulty is that although XML Schemas provide this information, it remains hidden when working with instance documents of this XML Schemas.
Moreover, there are more complex semantics encoded in the textual definitions of the Rights Data Dictionary. They are needed each time a programmer is developing an ODRL application and thus they must be "manually" interpreted repeatedly. The idea is to make the ODRL semantics explicit in order to exploit ODRL hidden semantics and to attach more complex semantics to it. All these would facilitate ODRL applications implementation.
This objective can be accomplished using Semantic Web ontologies. OWL is used as the tool to formalise ODRL semantics. This formalisation will be accomplished in two phases. First, the lightweight semantics encoded in the ODRL XML Schemas will be translated to OWL ontologies that make them explicit. The XML Schema to OWL mapper described in the XML Semantics Reuse section performs this translation, which is detailed in the ODRL XML Schemas to OWL section.
Then, it is time for the semantics informally written down as textual definitions. It is difficult to formalise them but even if the formalisation is incomplete, they will greatly facilitate ODRL applications development. In order to facilitate this formalisation, the copyright ontology semantics are reused. The terms defined by the ODRL OWL ontologies are connected to the semantically equivalent terms in the copyright ontology. Therefore, the copyright ontology rich semantics are "propagated" to the ODRL ontologies. This last step is detailed in the ODRL to Copyright Ontology Mapping section.
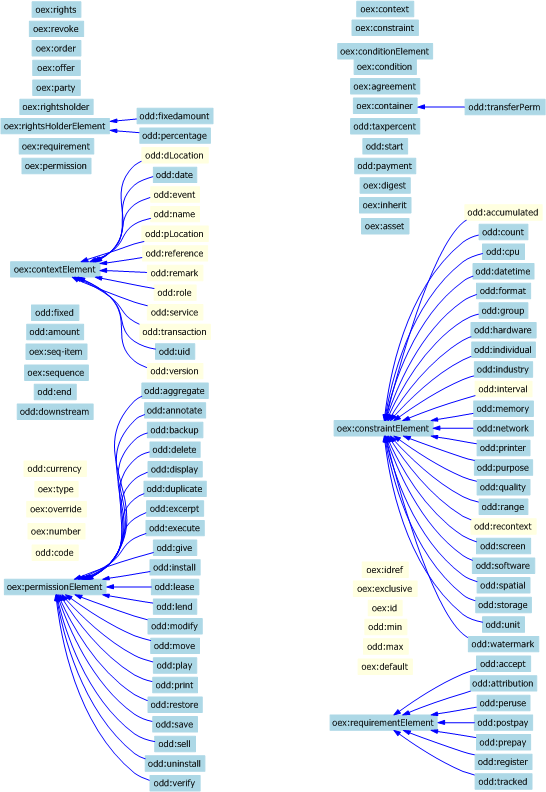
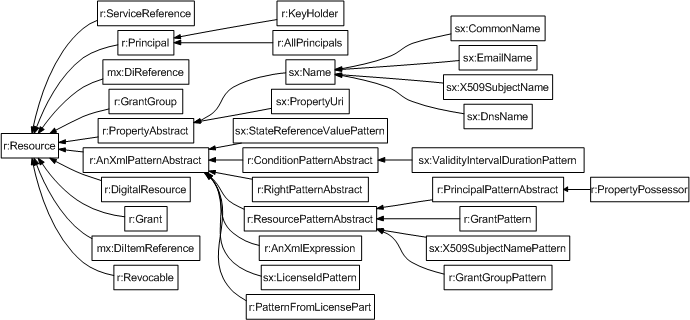
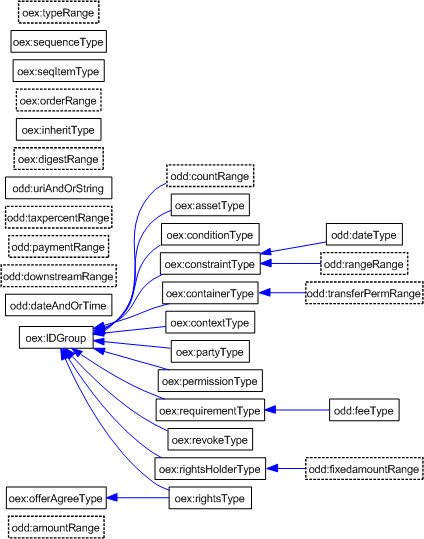
The XSD2OWL mapping has been applied to both ODRL XML schemas. They define a quite flat set of hierarchies for complexTypes and elements. ComplexTypes are translated to OWL classes and they build up a hierarchy from their extension and restriction base relations as shown in Figure. Note that the "Range" suffixed and line-dotted classes correspond to implicit complexTypes, i.e. complexTypes defined implicitly inside element definitions that do not receive a name in the XML schema. The classes defined in the EX-11 schema are prefixed with "oex" and the ones from the data dictionary DD-11 with "odd".
On the other hand, elements and attributes are mapped into properties and organised hierarchically as specified by the substitutionGroup relation between elements as shown in Figure. Dark-filled properties correspond to object properties, i.e. owl:ObjectProperty, and light-filled ones to datatype properties, i.e. owl:DatatypeProperty. It has not been necessary to use rdf:Property because all elements have either simpleType or complexType values but not both.
The result of the XML Schema to OWL mapping is a complete OWL ontology for the ODRL language that makes the implicit semantics explicit. The OWL files for the ODRL Ontology are available at the ODRLOntos website. The simplest benefit of the ODRL Ontology is that it can be used to perform semantic queries that take into account the hierarchies of elements and complexTypes. This and other advantages of ODRL semantics formalisations are detailed in the ODRL Ontology Benefits section.
Applications usually operate over ODRL instances, i.e. XML documents instantiating the ORDL XML schemas. Therefore, in order to take profit from the just formalised semantics, it is necessary to map the XML instances to the semantic enriched form, i.e. to RDF metadata that instantiates the OWL ontologies just created.
The XML2RDF mapping described in the XML to RDF section resolves this. It receives the XML metadata for ODRL rights expressions and produces the RDF graph that models the corresponding XML tree. As it has been shown, the RDF graph is enriched with the XML Schema hidden semantics. Now, Semantic Web tools can easily put the ODRL XML Schemas semantics into practice.
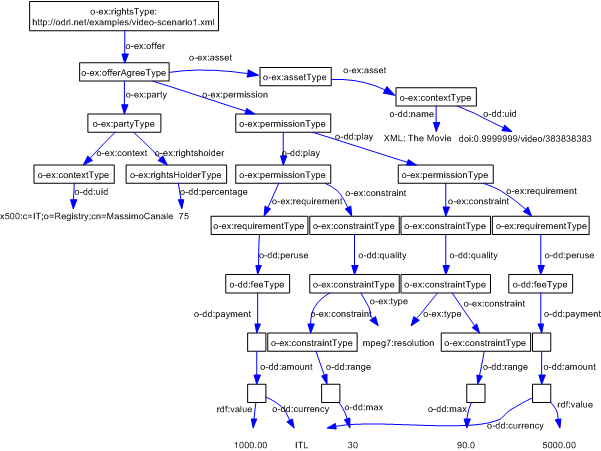
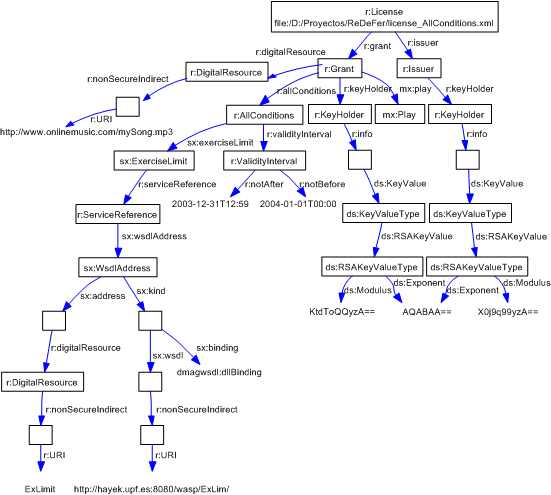
Figure shows an example of RDF graph produced from an ODRL XML license example taken from the ODRL 1.1 specification [Iannella02]. As it can be seen, the graph models the original XML tree. The properties in the graph mimic the elements that compose the XML instance metadata. The graph is enriched with the corresponding types for the subject and objects as specified in the ODRL OWL ontology generated from the ODRL XML Schemas.
The first step of ODRL semantics formalisation provides the lightweight semantics implicit in ODRL XML Schemas. Moreover, it provides the anchor points where we are going to attach the more detailed semantics formalised from the textual definitions of the ODRL Data Dictionary. The detailed semantics are written down as text so, in order to extract them, we would need natural language processing (NLP) methods. However, NLP techniques are not advanced enough to extract the intended semantics from the short descriptions of the Data Dictionary.
Therefore, it is necessary to take a different approach. An accurate reading of the definitions together with the whole ODRL specification has been done, i.e. automatic means have not been used. This reading is intended to interpret ODRL semantics in the framework of the Copyright Ontology contributed in the Conceptualisation chapter.
The Copyright Ontology is also a OWL web ontology that provides a general semantic framework for the copyright domain. The concepts defined in the Copyright ontology are related to the concepts defined in the ODRL Ontology in order to help formalising the ODRL semantics as interpreted from the ODRL specification.
First of all, in order to facilitate mappings, some changes are introduced in the ODRL ontologies that were automatically generated from the ODRL XML Schemas. As it has been shown in the ODRL classes Figure and ODRL properties Figure, properties, and correspondingly the ODRL XML schema elements, are more richly structured than classes, and consequently the ODRL XML schemas complexTypes.
The common situation for ontologies is the reverse one. Classes use to have richer hierarchical structure than classes and this is the case for the Copyright Ontology. Therefore, in order to facilitate mappings, the ODRL classes' hierarchy is enriched. No supplementary knowledge has been introduced. The objective is simply to replicate the properties hierarchy structure in the classes' hierarchy.
The current lack of structure is because ODRL does not define more specific complexTypes for "requirementType", "permissionType" and "constraintType", since they are not needed while working with XML. On the other hand, the corresponding elements, i.e. "requierementElement", "permissionElement" and "constraintElement", have more specific elements that appear as their subproperties in the OWL ontology, i.e. play, software, prepay, etc.
Therefore, in order to replicate structure, we introduce a new class for each one of these properties and define the class as a subclass of the corresponding existing class. For instance, the "playType" class is introduced, corresponding to the "play" property, and it is defined as subclass of "permissionType". The same is done for all the subproperties of "requierementElement", "permissionElement" and "constraintElement". The same applies for "offer" and "agree", both related to the "offerAgreeType" complexType. The corresponding "offerType" and "agreeType" are introduced.
As the last preparatory step, we have also reintroduced in the ODRL ontologies all the abstract elements defined in the ODRL specification but not present in the XML Schemas. Consequenly, as detailed previously, we have also introduced the corresponding classes in order to replicate the new properties in the classes hierarchy. They are "use", "reuse", "transfer" and "asset management" as "permissionElement" subproperties; "interaction", "fee" and "usage" as "requirementElement" subproperties; "user", "device", "bounds", "aspect", "target", "temporal" and "rights" as "constraintElement" subproperties.
Thanks to the previous preparatory step, the ODRL Ontology is easier to map to the Copyright Ontology. The mapping has not been implemented completely. What is detailed in this work are the principles and techniques that allow implementing them mechanically. Just some of them have already been implemented as examples.
The integration is performed using two techniques. First, for simple cases, it is possible to connect ontology concepts using OWL primitives for concept inclusion and equivalence, e.g. subClassOf, subPropertyOf, equivalentClass, equivalentProperty, sameIndividualAs, etc.
These are some simple mapping examples; "o-ex" prefix refers to concepts generated directly from ODRL-EX XML schema, "o-dd" for ODRL-DD XML schema, "o-ont" for the extensions generated during the previous preparatory steps and "co" for concepts in the Copyright Ontology:
However, the previous technique is only possible when we are mapping one concept from an ontology to one concept in the other ontology. When the conditions for the mapping are more complex, the solution is to use the semantic rules described in the Semantic Web Rules section. Rules are particularly useful when the mapping must cope with a difference in the manner the concepts are structured in the mapped ontologies.
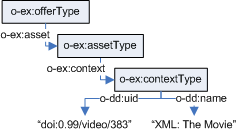
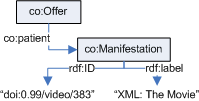
For instace, the ODRL context element is not used in the Copyright Ontology. Web ontologies use the RDF identifier (rdf:ID) instead of the ORDL one (o-dd:uid) and RDF identifiers are directly attached to the concept they identify. In ODRL words, this means that the identifier is a direct attribute of the asset. The same applies to the rest of the context model elements.
Therefore, the context element must be removed when mapping an ODRL instance to the Copyright Ontology. However, it is easier to convert the context of a contextualised type because it has all this information directly attached, while the contextualised type is empty. For instance, a contextualised description of an offer asset shown in Figure is transformed using the previous simple mappings in conjunction with the mapping rule in Table to the Copyright Ontology-aware description shown in Figure.
ODRL context to Copyright Ontology mapping rule
|
o-ex:asset(?x,?y) ∧ o-ex:assetType(?y) ∧ o-ex:context(?y,?z) |
The previous mappings exemplify the principles that would guide a complete mapping from the ODRL Ontology to the Copyright Ontology. It remains future work as it is detailed in the Future Work chapter. Now it is time to show the benefits of ODRL Ontology and its mapping to the Copyright Ontology.
The more direct benefit of the formal semantics provided by the ODRL Ontology is that it is possible to perform semantic queries, which are more powerful than syntax-based ones like XPath. In order to exemplify, we will retake the introduction problem about a query for retrieving the constraints affecting an ODRL rights expression. When we are working with the XML version, we need 23 different XPaths in order to retrieve all possible kinds of constraints.
This is necessary because, although XML Schemas capture some semantics of the domain they model, XML tools are based on syntax. The captured semantics remain implicit from XML processing tools point of view. Therefore, when an XQuery searches for a constraint, the XQuery processor has no way to know that there are other constraints, which can appear in its place. In other words, they are more concrete segment types.
With the RDF version connected to the ODRL ontologies, a semantic query for the superproperty of all constraints, i.e. o-ex:constraintElement, will be automatically propagated in order to retrieve all the particular constraints defined as its substitutionGroup in the XML schema, and consequently defined as its subproperties in the OWL ontology. The resulting hierarchy can be seen in the ODRL properties hierarchy shown in Figure.
Semantic queries reduce the amount of source code required to develop ODRL tools and make it very easy to maintain because existing generic semantic queries can cope with changes in more specific parts of the ODRL specification without being affected. For instance, new kinds of constraints might be introduced without disturbing an previous application that implements a semantic query for oex:ConstraintElement.
The new constraints will be defined as substitutionGroup of oex:ConstraintElement and thus they will be mapped to subproperties of the corresponding property. The ODRL tools is always feed with the last version of the ODRL Ontology, which does not require any implementation change, so it will automatically retrieve the new constraints as the query is propagated to all the existing subproperties.
Another point is the ODRL mapping to the Copyright Ontology that makes a substantial part of the more complex part of the ODRL semantics formal. This might reduce ambiguities, or at least highlight possible ambiguous points. Moreover, there are new application development facilities. In addition to the semantic queries benefits shown before, other semantics-enabled tools can be used. One of the most promising tools is Description Logics (DL) [Pan04].
OWL is based on DL so it can be directly fed into DL classifiers. Classifiers are specialised logic reasoners that guarantee computable results. DL classifiers are used with the Copyright Ontology in order to check copyright uses against the usage patterns specified in copyright agreements or offers as detailed in the Implementation section. This facilitates checking if a particular use is allowed in the context of a set of licenses or finding an offer that enables it, once an agreement is reached.
DL classifiers can be directly reused so there is no need to develop ad-hoc applications to perform this function. Moreover, as they are completely OWL semantics aware, the Copyright to ODRL ontologies mappings enables their use in order to check uses against ODRL licenses, even if they are in XML form. XML ODRL licenses can be mapped to RDF using XML2RDF and then, through mappings, are connected to the Copyright Ontology semantic framework.
As it has been shown, the Semantic Web approach to ODRL semantics formalisation has started to give its fruits. Even the first step of semantics formalisation, during which the implicit semantics of ODRL XML Schemas have been formalised, has proved very useful simply by making semantic queries possible.
The second step, during which more semantics are being defined, is showing promising results and it can greatly enlarge semantic benefits for ODRL applications implementation. Moreover, it has also allowed validating and enriching the Copyright Ontology. It has been possible to find an anchor point where ODRL Ontology concepts can be related to Copyright Ontology ones. In some cases, they were to general so more specialised intermediate concepts have been added.
To conclude, it is important to remark that all this work has been done for the current version of ODRL, version 1.1. This version was intended for XML representation and this has made the connection of ODRL ontologies to the Copyright Ontology harder. For future versions of ODRL, it might be interesting to consider this possibility, which might enable a more complete formalisation using web ontologies.
MPEG-21 is another Digital Rights Management initiative. It is the MPEG standardisation framework for digital content management. As it has been introduced in the MPEG-21 section, MPEG's rights modelling part is divided into the Rights Expression Language (REL) and the Rights Data Dictionary (RDD). The REL part of MPEG-21 is, like ODRL, based on XML Schemas. It is even more complex than ODRL as shown in Table, where the attributes, elements and complexTypes are counted for the three main MPEG-21 XML Schemas. There are 330 components for 127 in ODRL.
Named XML Schema primitives in MPEG-21 REL
|
Schema |
REL-R |
REL-SX |
REL-MX |
|
xsd:attribute |
9 |
3 |
1 |
|
xsd:complexType |
56 |
35 |
28 |
|
xsd:element |
78 |
84 |
36 |
|
Total |
330 |
||
For the XML Schemas that are part of MPEG-21 REL, the XML Semantics Reuse methodology has been also applied. The XML Schema to OWL has produced one OWL ontology for each REL XML Schema. However, this is not enough to put all REL hidden semantics into practice. That was enough with ODRL because it uses XML Schemas both for the language and dictionary definitions. However, the MPEG-21 dictionary (RDD) is not a XML Schema dictionary; it is an ad-hoc ontology. This poses additional difficulties to MPEG-21 applications development. The REL and the RDD are not integrated and RDD ontology requires specialised developments because it is not written using a common ontology language.
In order to integrate the RDD with REL, the MPEG-21 RDD ontology is also translated to OWL as it is shown in the MPEG-21 RDD Ontology section. Once this is done, this ontology is connected to the semantic formalisation build up from the MPEG-21 REL XML Schemas that are detailed in the next sections. Consequently, semantic queries will also profit from the RDD ontology semantics as it is shown in the MPEG-21 RDD Ontology Benefits section.
The same XML Semantics Reuse methodology than in the case of ODRL has been applied to MPEG-21 REL. There are three XML Schemas for MPEG-21 REL so all three have been mapped to OWL. On the contrary to ODRL Ontology, the resulting MPEG-21 REL Ontology has a more rich hierarchical structure. This is due to its greater size but also due to how the three schemas that compose the MPEG-21 REL are organised. There is the REL-R schema that corresponds to the language core entities. Then, there is the REL-SX schema that corresponds to the language standard extensions and, finally, the REL-MX schema that contains the multimedia specific extensions.
These schemas are organised as progressive semantic refinements, from the core concepts to the standard and multimedia specific ones. These corresponds to a richer hierarchy of concepts as more specific concepts are defined as specialisations of the more general ones established by the more general schemas. For instance, Figure shows the hierarchy of concepts that specialise the MPEG-21 REL "Resource" concept. As it can be seen from the concept prefixes, the "Resource" concept comes from the Core schema, so it is prefixed "r". There are other concepts also defined in the Core schema and prefixed with "r", which constitute the more general kinds of resource in MPEG-21 REL. There are also concepts prefixed with "sx" that come from the Standard Extensions schema. These are concepts that are more specific, all of them build on top of concepts that were previously defined in the Core schema. There are no resources defined in the Multimedia Extensions schema so there are not concepts prefixed with "mx".
The result of the mapping of the three XML schemas to OWL produces a complete OWL ontology for the MPEG-21 REL that makes its implicit semantics explicit. The complete MPEG-21 REL Ontology is not shown here due to space limitations but the OWL files for the MPEG-21 REL Ontology are available at the MPEG21Ontos website. The simplest benefit of the MPEG-21 REL Ontology is that it can be used to perform semantic queries that take into account the hierarchies of elements and complexTypes. However, the MPEG-21 REL was conceived to operate in conjunction with the MPEG-21 Rights Data Dictionary as it is shown in the MPEG-21 section. Therefore, the benefits of the ontological approach applied to the MPEG-21 standard are presented for both MPEG-21 REL and RDD in the RDD Ontology Benefits section.
Applications usually operate over MPEG-21 REL instances, i.e. XML documents instantiating the corresponding XML schemas. Therefore, in order to take profit from the just formalised semantics, it is necessary to map the XML instances to the semantic enriched form, i.e. to RDF metadata that instantiates the OWL ontologies just created.
The XML2RDF mapping described in the XML to RDF section resolves this. It receives the XML metadata for MPEG-21 REL rights expressions and produces the RDF graph that models the corresponding XML tree. As it has been shown, the RDF graph is enriched with the XML Schema hidden semantics. Now, Semantic Web tools can easily put the MPEG-21 REL XML Schemas semantics into practice.
Figure shows an example of RDF graph produced from an MPEG-21 REL XML license example taken from the MPEG-21 REL specification [ISO04c]. As it can be seen, the graph models the original XML tree. The properties in the graph mimic the elements that compose the XML instance metadata. The graph is enriched with the corresponding types for the subject and objects as specified in the ODRL OWL ontology generated from the ODRL XML Schemas.
In order to map the MPEG-21 REL Ontology to the Copyright Ontology, the same steps than in the case of the ODRL Ontology are necessary. However, for the MPEG-21 REL Ontology it is going to be easier because the complexTypes and elements hierarchies are identical and there is not the need to reproduce the elements hierarchy for the complexTypes. Then, in order to perform the mapping, it is necessary to implement the direct mappings based on OWL constructs for concept inclusion and equivalence, e.g. subClassOf, subPropertyOf, equivalentClass, equivalentProperty, sameIndividualAs, etc. Moreover, for the more complex mappings that include some structural changes in the way the information is related, it is also necessary to use the semantic rules described in the Semantic Web Rules section.
The ODRL Ontology mappings exemplify the principles that would guide a complete mapping from the MPEG-21 REL Ontology to the Copyright Ontology. It remains future work as detailed in the Future Work chapter. The benefits and conclusion of the MPEG-21 REL Ontology are presented, in conjunction with those for the MPEG-21 RDD Ontology, in the MPEG-21 RDD Ontology section.
The MPEG-21 RDD Ontology provides an ontological approach to the Rights Data Dictionary (RDD) part of MPEG-21. In order to build the ontology, the terms defined in the RDD specification have been modelled using OWL, trying to capture the greatest part of its semantics. On the contrary, to the ODRL and MPEG-21 ontologies, the MPEG-21 RDD is not based on XML Schemas so an ad-hoc methodology has been used to map it to OWL. The resulting ontology allows formalising a great part of the standard and simplifying its verification, consistency checking and implementation. During the RDD Ontology construction process, some integrity and consistency problems were detected, which even have led to a pair of standard corrigenda.
Additional checks were possible using Description Logic reasoning in order to test the standard consistency. Moreover, the RDD Ontology is now being used by the MPEG-21 RDD standardisation members as a tool to help verifying the standard and guide its extension. Moreover, the ontology makes automatic to integrate the RDD with other parts of MPEG-21 also mapped to OWL, e.g. the MPEG-21 REL Ontology. Finally, there are the implementation facilities provided by the ontology. They have been used to develop MPEG-21 licenses searching, validation and checking which combine the functionalities of the MPEG-21 REL and RDD ontologies. Existing ontology-enabled tools as semantic query engines or logic reasoners facilitate this.
The objective of the RDD Ontology is to translate the RDD terms descriptions from its current textual representation in the standard to a machine processable representation using the semantic web paradigm. The set of all the predefined classes and properties defined by OWL and RDF Schema are the building blocks used to model the RDD semantics.
In the RDD Specification Analysis section, a study of the RDD specification is presented. Then, in the RDD to Web Ontology Mappings section, it is shown how, first RDF Schema and afterwards OWL, can be used to capture RDD terms definitions and a great part of their semantics. RDF Schema is capable of modelling only a fraction of the RDD semantics. This fraction is augmented when the constructs introduced by OWL are also used. Therefore, two versions of the ontology can be produced. The simpler one uses RDF Schema and the more complex one uses OWL.
The RDD Specification [ISO04b] defines a set of terms, the "words" in the vocabulary of a rights expression language. The RDD Specification is self contained so all the terms that it uses, even the relating terms, are defined in it. For each term, its description is composed by a set of attributes:
From the RDD Specification analysis two kinds of attributes can be detected. The first group is composed by those attributes with unstructured values, i.e. textual values. They can be easily mapped to predefined or new RDF properties with textual, i.e. literal, values.
The first option is to try to find predefined RDF properties that have the same meaning that the RDD term attributes that are being mapped. When this is not possible, the RDFS constructs will be used to define new RDF properties to which the corresponding attributes will be mapped. These properties are defined in the RDD Ontology namespace, "rddo".
The mappings of this kind are shown in Table. Note that the Dublin Core [Dekkers03] RDF Schema is also reused in the RDD Ontology. The Dublin Core (DC) metadata element set is a standard for cross-domain information resource description. The DC RDF Schema implements the Dublin Core standard.
Mappings for the RDD attributes with text value
|
RDD Attribute |
RDF Property |
Kind of RDF property |
|
Headword |
rdf:ID |
Predefined in RDF |
|
Synonym |
rddo:synonym |
New property defined in the RDD Ontology |
|
Definition |
dc:description |
Predefined in Dublin Core RDFS |
|
MeaningType |
rddo:meaningType |
New property defined in the RDD Ontology |
|
Comments |
rdfs:comment |
Predefined in RDFS Schema |
The other kind of attribute is the Relationships one. Its value is not textual. Firstly, it is categorised into five groups: Genealogy, Family, ContextView, Types and Membership of Sets. Each of these groups is composed by a set of relations that can be used to describe a term related to other terms in the RDD specification.
As it has been shown in the previous section, these groups of relationships take different semantic points of view. The Genealogy, Types and Membership of Sets groups comprise relationships with semantics almost equivalent to RDF Schema and OWL ones. The semantic equivalences have been deduced from RDD, RDF Schema and OWL specifications.
The relations in this groups that can be mapped to RDF/S are presented in Table. There is also a short description and the equivalent RDF property used to map them in the RDD Ontology. Only the RDD relations with an equivalent property in RDF Schema are mapped at this level, i.e. IsTypeOf, IsA, HasDomain and HasRange. The other relations have associated semantics that do not have equivalence in RDF Schema. Therefore, if the mapping is restricted to the possibilities provided by RDF Schema, then we get an incomplete ontology, i.e. it does not capture all the available semantics of RDD. However, on top of RDF Schema, more advanced initiatives like OWL have been developed.
Using OWL ontology building blocks, some of the previously unmapped RDD relations can be mapped to the RDD ontology. In Table they are presented together with a short description and the equivalent OWL property used to map them in the RDD Ontology. With OWL, almost all relationships can be mapped.
Only Is and IsPartOf relations do not have equivalents in OWL. Therefore, new properties in the RDD Ontology namespace have been created to map them. Another alternative is to reuse other ontologies, as it has been done with Dublin Core. In this case, mereological (IsPartOf) and quality (Is) notions are needed. For instance, they can be reused from the DOLCE [Gangemi02] foundational ontology. For IsPartOf the equivalent is "dolce:part-of" and for Is it is "dolce:has-quality".
Mappings for relationships in the Genealogy,Types and Membership of Sets groups to RDF
|
RDD relation |
Short description |
RDF |
|
IsTypeOf |
Builds the hierarchy of term types |
rdfs:subClassOf |
|
IsA |
Relates an instance term to its type |
rdf:type |
|
HasDomain |
Defines the source term type for relations |
rdf:domain |
|
HasRange |
Defines the target term type for relations |
rdf:range |
|
IsMemberOf |
The RelatingTerm from Member to Set |
rdfs:member |
Mappings for relationships in the Genealogy, Types and Membership of Sets groups to OWL
|
RDD relation |
Short description |
OWL |
|
Is |
Relates resources to ascribed qualities |
rddo:hasQuality |
|
IsEquivalentTo |
Relates two equivalent terms |
owl:equivalentClass |
|
IsOpposedTo |
Relates two opposite terms |
owl:complementOf |
|
IsPartOf |
Relates a terms that is part of another term |
rddo:isPartOf |
|
IsAllowedValueOf |
Relates allowed values to a type term |
Inverse of owl:oneOf |
|
HasType |
The RelatingTerm from Archetype to Type |
Inverse of rdfs:subClassOf |
|
IsReciprocalOf |
For relation terms defines the relation term that captures the inverse relation |
owl:inverseOf |
For the rest of the relationship groups, a part from Genealogy, there is no equivalent relations in the RDF Schema plus OWL domains. This is because these relationships are based on different kinds of semantics than those used in RDF Schema and OWL. Therefore, the approach is to map them to new properties in the "rddo" namespace.
To conclude the mappings, it is also necessary to map RDD terms to Web ontology concepts. The previous mappings only cover the attributes that relate them. This has been postponed until now because Web ontology languages discern the RDD terms into three kinds: classes, properties and instances. The distinction is not made in RDD but it can be deduced from the term attributes.
If the term Relationships attribute includes HasDomain or HasRange relationships, it is clear that this terms must be mapped to a rdf:Property. This is a necessary and sufficient condition because all terms referring to relations have at least one of these relationships.
Otherwise, the term is a class or an instance. It will be mapped to rdfs:Class if it has a IsTypeOf relationship or if there is no IsA relationship. If there is an IsA relationship but not IsTypeOf relationship, then it will be mapped to an instance, i.e. rdf:Description. It can be noted that it is possible to have a term that has both IsTypeOf and IsA relationships that is mapped to rdfs:Class. Therefore, as specified in the OWL reference [Dean04], the concrete OWL ontology produced is an OWL Full one.
The RDD to RDF Schema and OWL mappings that have been established before have been implemented by the RDD Ontology Parser [García03]. It is a Java implementation of these mappings using Java regular expressions. Regular expressions are used to define patterns that detect the RDD part of the mappings. When patterns match, the corresponding RDF is generated in order to build the RDD Ontology.
Finally, once attributes have been mapped, they are used to discern the processed term as an rdfs:Class, a rdf:Property or an instance, rdf:Description. The input of the the RDD OntologyParser is a plain text version of "Table 3 - Standardized Terms" of the RDD standard [ISO04b]. The output constitutes the the RDD Ontology Web ontology available at the MPEG21Ontos website. For the other relationships, a direct mapping to a new property with the same name in "rddo" namespace is implemented.
However, these relationships do not remain isolated in the resulting ontology. As all RDD terms are defined using RDD, relating terms are defined using relationships in the Genealogy group. Therefore, the RDD Ontology includes information about domain and range restrictions, relationships hierarchical organisation, etc.
The benefits of the MPEG-21 RDD Ontology are evaluated in conjunction with the MPEG-21 REL Ontology. First, it has been possible to use the RDD Ontology to check the integrity and consistency of the ISO/IEC MPEG-21 RDD standard and to amend some of the problems detected. It has been easy to integrate MPEG-21 REL and RDD, as intended from the original MPEG-21 plans but difficult to the different approaches they have taken. The integration has been easy as soon as both were in OWL ontology form. Finally, as in the case of the ODRL Ontology, it has been possible to employ semantic queries and advanced reasoning tools in order to facilitate the implementation of MPEG-21 REL and RDD applications.
During the ontology development, ontology tools facilitated the detection of integrity and consistency problems in RDD. There were many references to undefined references and inconsistencies between different parts of the standard. Some of these initial problems were communicated to the MPEG-21 RDD working group and the RDD Ontology development process led to an initial revision [Barlas05] of the then recently published RDD ISO/IEC standard [ISO04b].
First, there were some inconsistencies between the textual RDD terms definitions and a figure showing the hierarchy tree of RDD act types. These inconsistencies were detected by comparing the figure included in the standard with a drawing of the Act hierarchy generated automatically from the RDD Ontology using the Protégé ontology editor and the OntoViz ontology visualisation plug-in.
However, the more important problems were related to the integrity issues of the standard. Some of the relationships and terms that were used in the terms definitions were not defined in it. Consequently, they have been added to the RDD Ontology, e.g. HasCoChangedResource, icoInteractor, IsInteractorInContext, etc. The integrity checks were performed with the help of the OWL validator vOWLidator.
Another testing facility once mapped to an OWL ontology is the consistency check provided by Description Logic (DL) [Pan04] reasoners. OWL is a Description Logic so DL reasoners can be directly used in order to reason with OWL ontologies. The only limitation is that reasoners only deal with two of the three OWL sublanguages, i.e. OWL DL and OWL Lite but not OWL Full.
As it has been said, the RDD Ontology is OWL Full so we have to take away some of the mapped constraints that make it Full prior to feeding it into the DL reasoner. This has been done deactivating some of the mappings in the the RDD OntologyParser and with the further assistance of Protégé combined with the Racer DL reasoner. The more important feature that has been deactivated is the "IsA" to "rdf:type" mapping in order to avoid OWL Classes or Properties that are instances of other classes.
The interesting thing has been that, after making the RDD Ontology an OWL DL ontology, we have detected 320 inconsistencies in it. All of them are due to inconsistencies between the classes and properties hierarchies. The consequence is that many property domains and ranges are inconsistent with the domains and ranges of the corresponding superproperties. For instance, the property IsAgentActingOn has domain Agent. The direct superproperty IsRelativeOf has domain Relative but Relative is not a superclass of Agent so there is an inconsistency in the IsAgentActingOn domain.
These results of our ontological analysis of RDD have been submitted to the MPEG standardisation group [García05d] and its discussion has started a process to revise the standard in order to fix these problems, which will lead to a new MPEG-21 RDD standard corrigendum.
The rights statements representation part of MPEG-21 is composed of the RDD, which defines the terms as it has been shown, but it also includes the Rights Expression Language (REL). The easiest way of explaining this is through a simile: the RDD provides the definition of the words while the REL provides a language to put these words together in order to build statements. However, it is difficult to put the MPEG-21 REL and RDD together into practice.
While the RDD is defined as an ontology, although a non-formal ontology language is used, REL is defined on the basis of a set of XML Schemas. This makes the integration between them very tricky. Our approach has been to take profit from the integration facilities provided by web ontologies. The REL XML Schemas have been also mapped to OWL and then easily integrated with the RDD Ontology using the OWL semantic relations for equivalence and inclusion: subClassOf, subPropertyOf, equivalentClass, equivalentProperty, sameIndividualAs, etc. In order to map the XML Schemas to OWL and XML instances to RDF, the XSD2OWL and XML2RDF mappings have been applied.
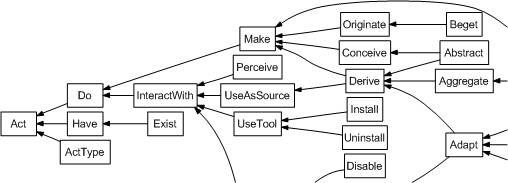
Once the REL and the RDD were integrated, it was possible to develop ontology-enabled applications that take profit from their formal semantics. This has been used to implement MPEG-21 licenses management tools. For instance, the acts taxonomy in MPEG-21 RDD, which is partly shown in Figure, can be seamlessly integrated in order to facilitate license-checking implementation. Consider the scenario: "we want to check if our set of licenses authorises us to uninstall a licensed program".
If we use a purely syntactic approach like XPath over MPEG-21 XML licenses, there must be a path to look for licenses that grant the uninstall act, e.g. "//r:license/r:grant/mx:uninstall". Moreover, as it is shown in the taxonomy, the usetool act is a generalisation of the uninstall act. Therefore, we must also check for licenses that grant us usetool, e.g "//r:license/r:grant/mx:uninstall". In addition, successively, we should check for interactwith, do and act. All this must be done programmatically, the XPath queries are generated after we check the RDD ontology.
However, if we use semantic queries, the existence of a license that grants any of the acts that generalise uninstall implies that the license also states that the uninstall act is also granted. This is so because, by inference, the presence of the fact that relates the license to the granted act implies all the facts that relate the license to all the acts that specialise this act.
Therefore, it would suffice to check the semantic query "//r:license/r:grant/mx:uninstall". If any of the more general acts were granted, it would match. For instance, the XML fragment "/r:license/r:grant/dd:usetool" implies the fragments "/r:license/r:grant/dd:install" and "/r:license/r:grant/dd:uninstall".
There are other application development facilities more sophisticated than the semantic queries benefits shown before. One of the most promising tools is Description Logics (DL) [Pan04]. OWL is based on DL so it can be directly fed into DL classifiers. Classifiers are specialised logic reasoners that guarantee computable results. DL classifiers are used with the MPEG-21 REL and RDD ontologies in order to check content uses against the usage patterns specified in copyright agreements or offers as detailed in the Implementation section. This facilitates checking if a particular use is allowed in the context of a set of licenses or finding an offer that enables it, once an agreement is reached.
DL classifiers can be directly reused so there is no need to develop ad-hoc applications to perform this function. Moreover, as they are completely OWL semantics aware, the Copyright to MPEG-21 ontologies mappings enables their use in order to check uses against MPEG-21 licenses, even if they are in XML form. XML MPEG-21 REL licenses can be mapped to RDF using XML2RDF and then, through mappings, are connected to the Copyright Ontology semantic framework.
The benefit of the MPEG-21 RDD and REL ontologies over other initiatives is that it is based on applying an ontological approach. This is done by modelling the RDD standard using ontologies. Ontologies allow that a greater part of the standard is formalised and thus more easily available for implementation, verification, consistency checking, etc.
The MPEG-21 RDD Ontology demonstrates the benefits of capturing the RDD semantics in a computer-aware formalisation. First, it has been possible to analyse the standard integrity and consistency with the support of ontology-aware tools that facilitate this issue, discovering inconsistencies that are in the process of being fixed in the standard. Then, it has been possible to integrate RDD with another MPEG-21 standard part, the Rights Expression Language (REL), in a common ontological framework. This framework facilitates the implementation of MPEG-21 tools.
We have shown our achievements using semantic query engines and Description Logic reasoners for license searching, validation and checking. The ontological approach has also made possible the development of advanced Digital Rights Management systems that integrate these tools in order to build semantic information systems, as the one presented in the Semantic DRM Systems section, and intelligent agents for assisted rights negotiation as detailed in the Negotiation Support section.
The objective now is to take profit from the abstraction and integration facilities of formal ontologies in order to cope with the RDD standard problems. First of all, the RDD Ontology is being used in order to extend RDD capabilities in a consistent and more informed way. Some communities might find that there are some unsatisfied requirements in the current RDD. This is completely normal as it is impossible to cope with all the requirements of communities as big as the ones that might be interested in the MPEG-21 standard.
The MPEG-21 RDD standard specifies mechanisms for standard extension. However, it is difficult to put these mechanisms into practise. The size of the standard makes it very complex for people outside the standardisation process to manipulate and extend it in order to satisfy their particular needs. This is why we have started to use the RDD Ontology as an assistance mechanism for RDD testing of new requirements. The RDD Ontology is used together with ontology rendering tools in order to navigate the RDD hierarchy of concepts, detect the part of it where the new concept might be situated and even produce a graphical drawing of it.
Another future line is to exploit the integration possibilities of OWL in order to connect the RDD Ontology with more general ontologies, as the Copyright Ontology, or rights data dictionaries of other rights expression languages like ODRL. The objective here is to build an ontology-based framework that allows integrating these initiatives, making them interoperable and enrich them with the possibilities offered by formal ontologies. This might lead to levels of interoperability that allow combining different RELs and RDDs in a totally uncoupled way.
Digital Rights Management (DRM) is a
complex domain. The DRM field is structured by evolving regulations, practises,
business models, etc. Therefore, DRM Systems (DRMS) are very difficult to
develop and maintain. The ontological approach to DRM contributed by this work
helps dealing with DRM complexities as it has been already shown in the
previous validation sections. However, these ontologies need to be put into
practice in order to show their benefits.
The NewMARS DRMS [García04], formerly
called MARS [García01], is semantics-enabled
DRM system that puts the ontology-based approach to DRM into practice and
validates its usefulness. A knowledge-oriented approach has been chosen in
order to make this development capable of dealing with this complicated domain.
This requirement and the objective of easy Web integration have made the
Semantic Web technologies the best choice.
Semantic metadata is associated to copyright governed content using URIs and it
is structured using web ontologies. There are descriptive, rights and
e-commerce ontologies for the different views on copyright content. Semantic
enabled metadata is then used to facilitate content providers to publish content
offers and customers to find and automatically negotiate purchase conditions. All
this is performed under the copyright governing premises.
All NewMARS modules are interrelated using the ontologies shared semantics.
This has allowed developing very flexible project infrastructures that
facilitates easy adaptation to new copyright e-commerce scenarios.
This Semantic DRMS tries to make a new contribution to the DRM field. DRM has been strongly affected by the digital era changes. Even now, all the new situations related to copyrighted content arisen from digitalisation and the Internet has not been satisfactorily resolved.
Some of these problems are faced by current initiatives trying to solve interoperability between Digital Rights Management (DRM) systems. DRM systems started from isolated and proprietary initiatives. However, they are lately moving to a web-broad application domain due to the World Wide Web effect on the digital content market.
There are many other initiatives but, basically, all have one thing in common, they work at the syntactic level. Their approach is to make a formalisation of some XML DTDs and Schemas [Yergeau04] that define a rights expression language (REL). In some cases, the semantics of these languages, the meaning of the expressions, are also provided but formalised separately as rights data dictionaries (RDD). Rights dictionaries list terms definitions in natural language, intended for human consumption and not easily automatable.
However, this kind of syntactic approaches are not solving the problem as a whole. They do not scale well in really wide and open domains like the Internet. Therefore, the interoperability problems are reappearing, as it is very difficult to establish a one-fits-all standard.
Most probably, we are not going to see a clear winner in the REL battlefield, at least in the short time range. However, automatic processing means for the huge and heterogeneous amounts of metadata produced by DRM are required. The syntax is not enough when unforeseen expressions are met. Here is where machine understandable semantics come to help metadata interpretation to achieve interoperability.
Our idea is to facilitate the automation and interoperability of DRM frameworks integrating both parts, the Rights Expression Language and the Rights Data Dictionary. As it has been shown in this work, these objectives can be accomplished using ontologies, which provide the required definitions for the REL terms in a machine-readable form. Thus, from the automatic processing point of view, a more complete vision of the application domain is available and more sophisticated processing can be carried out.
Once the ontological framework based on the Copyright Ontology has been laid out, it is just a formalisation without utility if it is not put into practice. This has been the objective of the NewMARS project: to build a DRMS that takes profit from the advantages of the ontologies formalisations, which will facilitate the implementation of copyrighted content e-commerce solutions.
In order to put NewMARS into practice, what has been done first is to analyse the DRM business model. This business model defines the environment where NewMARS will fit, the actors with which it will interact and the interaction rules. The business model we have considered is presented in the Business Model section.
The NewMARS Project planning has been guided by the idea to make a knowledge-guided development, from a computer point of view. This implies transferring a great amount of the development effort from the functional model to the domain knowledge model.
Consequently, the number of application functions is reduced to some basic ones in charge of message interchange among the application parts. A user actions diagram detailing actors and functions is detailed in the User Actions Analysis section. Therefore, the focus is placed on the semantics of these messages.
As it has been introduced before, the Copyright Ontology is used as the basis of the knowledge model. Therefore, a great part of this effort has been already done and it is reused in NewMARS. There are only some small extensions to the knowledge model derived from the practical aspects of the project. More details about this are given in the Metadata section.
The e-commerce of copyright is guided by a business model that has emerged from the associated regulations framework, the commercial activity and the electronic means that have influenced it.
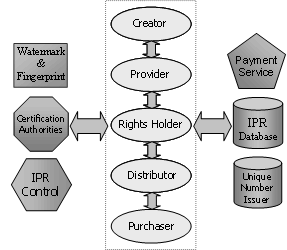
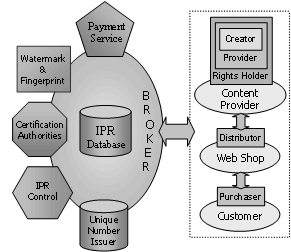
In order to build NewMARS upon a quite generic and flexible business model inspired by the one produced by the IMPRIMATUR project [Barlas95], the NewMARS business model identifies a set of basic roles and interactions among them. These basic roles are shown in the centre of Figure and they constitute a generic value chain.
In parallel, some support services have been also identified. They constitute the basic services that facilitate the IPR e-commerce activity. They are shown in Figure round the roles to which they give support along the whole value chain.
To facilitate the implementation of this model, it has been combined with a broker-based e-commerce model that has been extensively tested in previous research [Gallego98, Delgado99, García01]. The final broker-based business model implemented in NewMARS is shown in Figure.
The broker facilitates value chain actors access the DRM e-commerce services. Moreover, in the NewMARS scenario, actors have been simplified to three, each one playing one or more roles: Content Provider (it can play the Creator, Provider and Rights Holder roles), Web Shop (it plays the Distributor role) and Customer (it plays the Purchaser role).
In addition to the broker, the NewMARS project is also going to implement the Distributor role through a web shop. Consequently, there will be only two external actors: Content Provider and Customer. More details are given in the user actions analysis in the next section.
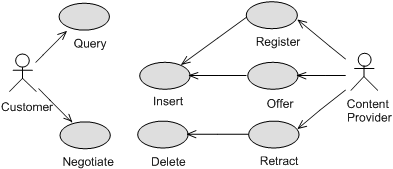
Figure shows the use cases that specify the relations among the external actors that have been identified and the application.
The user actions are detailed below:
The content information that is managed by NewMARS is modelled as metadata associated to resources. Moreover, a set of ontologies provide the required semantics. As it has been introduced before, the Copyright Ontology is used as the foundation for rights and e-commerce metadata.
However, descriptive metadata depends on the particular content that is managed. Due to project requirements, NewMARS was planned considering digital multimedia content. Therefore, ontologies about descriptive metadata for this kind of content where considered.
The MPEG-7 standard [Salembier02] was taken as the source for the descriptive ontology due to its coverage and relevance. MPEG-7 is based on XML Schema so the XML Semantics Reuse methodology was employed to generate a MPEG-7 OWL ontology [García05c], which was complemented with TV-Anytime ontologies also generated from their XML descriptions. All these ontologies are available from the MPEG-7 Ontologies website. This constitutes a big source of semantic multimedia metadata.
The previous descriptive ontology provides a quite satisfactory framework for multimedia content description. The multimedia specific aspects are complemented with the generic ones provided by Dublin Core [Dekkers03]. An example of RDF metadata description in NewMARS is shown in Table.
|
< xml
version="1.0" encoding="UTF-8" > <rdf:RDF
xmlns:rdf="&rdf;" xmlns:owl="&owl;" xmlns:dc="&dc;"
xmlns:mpg7="&mpg7;" <ipr:Work
rdf:about="urn:iswc:FF-Wind_Power"> <ipr:Fixation
rdf:about="urn:isan:FF-Wind_Power.mpg"> <ipr:Agree
rdf:about="urn:agreement:200505111210"> </rdf:RDF> |
Another key element about metadata in NewMARS is that it is expected to come from many different sources, i.e. metadata stores. Therefore, it is required that the metadata management processes implemented support this feature. However, from the outside, the users should experience an integral view of metadata so the metadata must be merged transparently.
In order to implement this feature, the best option is to use RDF metadata through all the NewMARS information flows. Therefore, NewMARS receives RDF metadata as input, manages it and also produces RDF metadata as output. When RDF metadata coming from different sources must be combined, the RDF graph model facilitates metadata integration that is reduced to a process of graph merging. Once integrated, the metadata graph can be serialized and sent to the output. More details about how this is implemented are shown in the Metadata Retrieval section.
Once the application domain has been introduced, this section details how the application has been developed. The driving force has been knowledge orientation. This has been materialised by prioritising application modules decoupling and basing module interrelation in shared semantics.
Web technologies, and more concretely Semantic Web tools, have been chosen as the more appropriate ones considering these requirements. First of all the following technological choices have been realised:
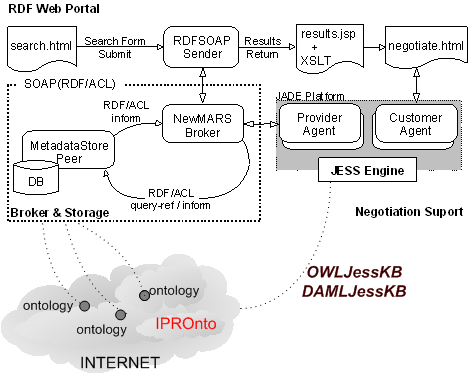
From the combination of requirements, design principles and technological choices, the architecture shown in Figure has emerged.
The architecture defines three main blocks:
As it has been introduced before, the broker block of NewMARS has a SOAP interface. However, this interface is only used for message transport. Thus, message semantics do not depend on different SOAP interface methods. Message semantics are determined by their structure and content.
The ACL Ontology is used to define message structure. The structure determines what to do with message content, which can be a query or metadata like those presented in the Metadata section. The actions that can be taken by the broker are at last supported by the metadata store elements that allow metadata storage and retrieval.
Message structure is based on the Agent Communication Language. ACL [FIPA02] defines a set of communicative acts that establish message intentionality, i.e. its pragmatics. ACL also defines attributes that determine message characteristics. Some of these communicative acts are used in messages sent to the broker because they correspond to the user actions it manages:
Metadata Storage
The different broker actions end up with an access to the metadata storage system. As it has been shown in the architecture, it has been separated from the broker in different independent modules. Communication between the broker and the selected metadata storage peer is also performed by means of ACL structured messages.
The message communicative act tells the store peer how it has to interpret it. The content of inform messages is inserted or deleted and query-ref messages content is interpreted as query sentences.
The store peer is supported by a RDF store that is in charge of really storing the metadata or retrieving the stored metadata corresponding to the pattern determined by the query sentence. The store peers make the broker and all the application independent from the particular RDF store used. Therefore, they show the same behaviour. They receive RDF metadata as input of Insert and Delete actions.
MetadataStore Peers are not only responsible for making the NewMARS system independent from the different metadata store particularities. Moreover, they are also responsible for converting metadata query results from the common table-like result sets to RDF metadata as it is detailed next.
As has been shown in the previous section, the Broker receives RDF metadata as input. This is a common behaviour of RDF stores so, in this case, little work has to be done.
On the other hand, as it has been stated during the application domain analysis, it is also very interesting to get RDF metadata as output from RDF stores so the whole information flow is done in RDF form. This has been justified as it facilitates the integration of metadata coming from different sources.
Moreover, if the web portal receiving the output from the NewMARS broker gets RDF metadata instead of table-like result sets, more information would be available in order to render this metadata to the user. In other words, the stored metadata semantics would not be lost in the query output and would arrive intact until the last information-processing step.
In this case there is some work to do as producing RDF metadata as query output is a very uncommon behaviour of RDF metadata stores. Query sentences are augmented by the NewMARS Broker with a special construct "graph(sentence, depth)". When this construct is sent to a store peer, it indicates that the store peer has to construct one or more RDF graphs from the resources selected with the query sentence.
This is done by retrieving RDF triples from the selected resource to the maximum depth specified. However, blank nodes are not considered when computing this depth; i.e. triples with blank node resources are always added if they are directly connected to selected resources or indirectly through a chain of blank resources.
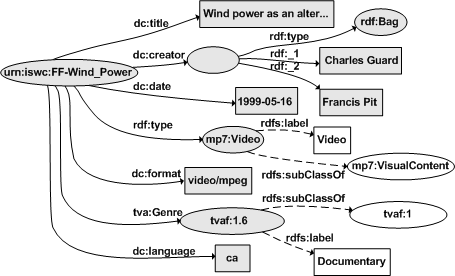
For example, see Figure. From a query that selects the resource "urn:iswc:FF-Wind_Power", the graph construction algorithm is applied with depth equal to one. All the grey filled resources and literals and the solid line properties are retrieved. The Bag anonymous resource is ignored in order to compute depth so its members and its type are also retrieved. On the other hand, the metadata attached to the Video and Documentary types, i.e. the white filled resources and literals and the dotted line properties, are not retrieved as they are at a greater depth.
Once the query response graph or graphs have been constructed, they are serialised as RDF/XML and encapsulated in the response messages. They are structured as inform messages containing the response metadata. As it has been shown, store peers allow a great independence from the concrete RDF stores used. Currently two RDF stores have been integrated: RDF Suite and Sesame.
The web portal has been developed as the user interface to the NewMARS functionality. The application has been developed based on the interchange of RDF messages with SOAP transport. Therefore, the portal must have a mechanism to encapsulate user interactions as RDF/ACL messages and send them to the broker by SOAP. Moreover, the responses to user interactions are made visible to the user by translating them to HTML. The web portal functionality is detailed in the next subsections.
This is the module responsible for the interaction between the portal and the broker. It is a servlet that receives user commands encoded as HTML form submissions. The form parameters are transformed into RDF triples, one for each parameter. All the triples have the same resource that identifies the current command. The properties are the parameter names and the resources their values.
The triples are serialised as RDFXML that is inserted into a new SOAP message in order to be sent, as shown in Table. The RDF content of the messages is built from the parameters received from the HTML forms through which the users interact with the system. Three basic forms can be identified: Query, Register/Offer and Retract.
SOAP envelope used to transport RDF/ACL messages
|
<SOAP-ENV:Envelope xmlns: > |
This form is composed by a set of fields relative to the attributes that finally will compose the RDF/ACL message that the RDFSOAPSender is going to generate. The available fields in the Query form are:
Table shows an example of RDF/ACL message built from a query form submission. It is an RQL query that retrieves metadata associated to offers that allow access to multimedia contents. The response is redirected to a web page that will format the output RDF metadata as HTML.
Example of RDF/ACL message built from a query form submission
|
<rdf:RDF xmlns:acl="http://daml.umbc.edu/acldaml"
...> |
This form is used to tell the broker the IP descriptive, rights or e-commerce metadata to be inserted in the system. It is like the previous form. The only changes are performative, inform or inform-ref, and language that now is RDF/XML in order to reflex that the content is RDF metadata.
The result web pages use XSL style sheets [Adler01] in order to transform the RDF metadata form response messages into HTML that can be shown by the web portal. There is a basic style sheet responsible for transforming each RDF description in the response metadata into an HTML table.
Each row corresponds to one property directly associated to the description. The first column is the property id and the second column is the property value. If the value is another resource, a sub-table is recursively inserted and the whole table construction process is repeated.
This basic XSL style sheet is then combined with particular ones that complete HTML layout in order to particularise output to the special needs required. An example of complete HTML layout of a RDF encoded offer is shown in Figure.
As has been shown in the Metadata Retrieval section, the metadata that is rendered is collected by building graphs from the selected resources to a given depth, commonly with depth one. In many cases this produces bunches of metadata with the relevant information for the posed query. However, sometimes it is necessary to get deeper in the graph and retrieve more metadata.
In order to facilitate metadata navigation, the XSL style sheet also produces HTML links for all the resource URLs. This links correspond to queries to the NewMARS broker for metadata about the clicked resource. Then, a pop-up window is opened showing the new metadata detail. The same XSL style sheet is applied to it so new HTML links are generated and they allow continuing the RDF metadata browsing experience through HTML. It can be tested on-line in the NewMARS website.
Agents technology is used to perform negotiation. Negotiation is the last customer action. It is performed once the customer has located the desired content and the corresponding offer that is going to be negotiated. Offers can be directly accepted, rejected or negotiated.
We have chosen the JADE multiagent platform. In order to reason about facts coming from messages, JESS (Java Expert System Shell) [Friedman-Hill03] has been used because it is easy to make it work together with JADE.
If the customer wants to negotiate the offer, he can choose a personal agent that will intermediate between the customer and the content provider agent. Customer and content provider agents are JADE agents controlled by the expert system. They negotiate the license offers.
The negotiation protocol is controlled by JESS and this allows a dynamic negotiation between the agents, who make offers and counteroffers, and it allows to process licenses. There are two main phases in the negotiation and they are introduced in the next subsections. More details about the negotiation support part are given in Rosa Gil s PhD thesis [Gil05a] and related papers [Gil03, Delgado02b].
Once the customer has chosen his representative agent, it is created and all the necessary data is loaded in the expert system. The metadata that models the negotiated offer and its context is loaded together with all the ontologies that define the concepts used by the metadata.
As has been already shown, all is expressed in RDF and OWL. In order to operate with JESS, all the metadata and ontologies are imported using OWLJessKB [Kopena03]. After that, the negotiation protocol and policies are also loaded. They are modeled as a set of rules in JESS format.
The protocol rules govern the timing of the different negotiation phases. On the other hand, the policy rules support the decision process of the agent. For instance, buy or sell only when a condition about price or duration is achieved.
This is an important feature because it allows us to determine important contract parameters as duration, prices and so on. Thus, we get a dynamic negotiation mechanism because negotiation policies can be easily changed and configured.
In this phase, the negotiation is finally carried out. The customer agent contacts the agent that is in charge of the offer negotiation. This is done using the information captured in the initial offer. The "agent" case role of the "Offer" action identifies the corresponding agent using a JADE identifier.
The content provider agent that is responsible for negotiating the offer is the representative of the content provider that made the offer. It is ready to handle negotiations and pre-configured with the desired negotiation policy.
When it is contacted, it retrieves the negotiated offer from the NewMARS broker. It is loaded together with the received counteroffer and the required ontologies in the JESS engine that governs its behaviour.
The customer will then use the customer agent as the intermediary between him and the content provider agent. The customer agent can be more or less interactive, i.e. more or less autonomous. On the other hand, the content provider agent is autonomous and thus it takes decisions completely on its own, as specified in its negotiation policy.
The negotiation process goes on through the corresponding protocol as a series of offers and counteroffers. The outcome can be an agreement if both parts agree on the offer conditions. These conditions will then constitute the license that is digitally signed by both parts. On the other hand, the negotiation process can fail if any part leaves the process.
The main conclusion from the NewMARS development has been the great benefits that can be obtained from a knowledge-oriented application. A high module independence based on the particular semantics has been achieved. This allows employing the same techniques for different domains by only adapting the conceptual framework, i.e. the ontologies that define the metadata structure.
For instance, in order to check NewMARS semantic capabilities, it has been also used with third party metadata. Concretely, it has been fed with RDF metadata from the MusicBrainz website. This project has its own ontology for the music domain, i.e. album, track, artist, etc. The only effort necessary in order to make NewMARS manage resources annotated with MusicBrainz metadata has been to connect its ontology with the NewMARS ontological framework.
This has been easy thanks to the foundation of NewMARS ontological framework in Copyright Ontology, a quite generic conceptualisation. Therefore, NewMARS can be easily configured to manage rights for any kind of copyrighted content.