The Semantic Web is an extension of the current web in which information is given well-defined meaning, better enabling computers and people to work in cooperation
Tim Berners-Lee, James Hendler, Ora Lassila [Berners-Lee01]
The Semantic Web is a vision: the idea of having data on the Web defined and linked in a way that it can be used by machines not just for display purposes, but for automation, integration and reuse of data across various applications
Tim Berners-Lee
Semantic Web origins from the premise that the Web is incomplete. It was posed by its inventor, Tim Berners-Lee [Berners-Lee00]. Even in his first designs of what the Web should be, there were ideas that did not come into reality in the version of the Web we currently have, which can be called the "Web 1.0".
In 1999, in conjunction with other people interested in creating a new web, Berners-Lee engaged a new trial to get a more complete picture of his initial Web dream. This new attempt was called the Semantic Web and has created a new community of research organised around the Semantic Web Interest Group at the World Wide Web Consortium.
In the last centuries, we have assisted to an increasing application of technologies to human communication. They range from the press or the telephone, to the digital worldwide publishing environment of the Web [Flichy95].
The processing, storage and distribution of information in society has become much more efficient since the introduction of the electronic media. This evolution shows successive stages, which are characterised by the growing complexity of the information processing system.
The first electronic mediums, such as telegraph and telephone, allowed one-to-one communication. Radio and television, the next generation mass media, allowed communication from one to many. The present electronic networks allow many-to-many communication.
On the horizon, next stages seem to be appearing. First, the computer network will become able to learn, that is, change the pattern of its connections. Then, the network will become able to think, that is, autonomously create new information [Heylighen96].
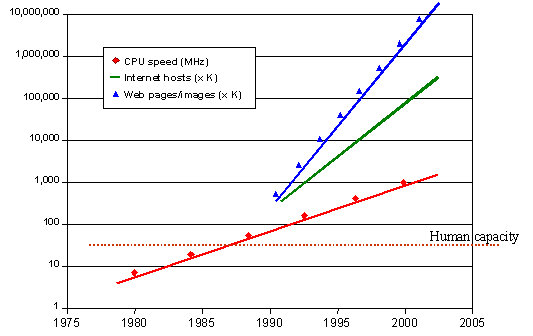
The Web can be considered the last most revolutionary idea in the human communication domain. It has just appeared, but its rapid evolution has driven it to a situation that seems to require new solutions. A comparison with other communications mediums is shown in Figure.
These solutions must resolve the problems that, paradoxically, have emerged due to its huge success. The World Wide Web is far away direct human capabilities, see Figure, and possible solutions to deal with this enormous amount of information seem to point to the learning and thinking network devised in the previous paragraph.
Currently the Web is merely an information-publishing medium directed towards human consumption. However, as it has evolved and grown, more and more automation solutions have been necessary to allow practical use.
In the Web, computers and networks settle the information space. However, their abilities are not exploited. Until now, communication mediums have not had advanced processing capabilities to manage the information that flow through them.
The Web has this kind of processing capabilities, however, they are not currently exploited. Machines can access only a limited part of the exchanged information, basically its encoding. Thus, advanced information processing can be achieved only following an ad hoc approach.
Only humans are able to catch enough meaning from the information flow to decide how to process it. Programmers have tools to automate these decisions, but they are not expressive enough to provide an automatic framework. Consequently, they are continuously involved in the low-level development issues.
This limitation, common in the Information Technologies domain, is even worst in the Web. It is an open and heterogeneous framework, where millions of interactions happen each day. Some are simple repetitions of previous ones, but most of them are new meetings that require particularised configuration.
On the other hand, limitations of Natural Language technologies do not allow direct access of machines to information. Less ambitious steps are the best solution by now. Computers need explicit help to grasp some of the information meaning.
A first option could be to formalise web content, to use standard forms, sets of words and grammars of universal use in the Web. This is a difficult issue because these formalisations should be agreed globally for each kind of web content.
Another option is to maintain current web contents while providing complementary data about data, i.e. metadata that describes content to machines. However, this does not directly resolve the problem, metadata must be also formalised to be understood by machines.
It would be easier, but not easy, to formalise this at the conceptual level. There are words that refer to the same concept and the same word may take different meanings, refer to different concepts, depending on the context in which it appears. Moreover, in a multilingual Web, conceptual metadata also facilitates multilingual interactions.
Therefore, all this can be accomplished providing semantic annotations of content. These annotations make data meaning explicit by situating it in a conceptual framework. Here, Knowledge Representation techniques are very helpful because there are specialised in formalising information at the conceptual level.
Knowledge Representation is a quite mature discipline, in fact with some millennia of evolution. Lastly, it has largely benefited from technology advances that have allowed its automation. However, it has lacked of big real world application environments where it can be fully applied.
Moreover, when it has been used in smaller domains, rigid operation has been enforced in order to maintain formalism compliance. Thus, due to these two initial restrictions, developed systems evolvability has been seriously compromised and results have been quite predictable.
On the contrary, the Web is a big and heterogeneous environment. On one hand, it provides a huge application space that, on the other hand, forces relaxed Knowledge Representation formalisms in order to obtain practical results.
Rigidity is not appropriate and new ideas based on free evolutionary-like patterns are being considered. The final idea is that, eventually, a world wide distributed knowledge system would emerge, what has also been called the global brain [Heylighen97], of which we may be seeing its first synapses.
In conclusion, the Semantic Web is new opportunity for both fields, traditional web and Knowledge Representation, where they can operate in conjunction. Benefits from their join application have just started to be explored.
The question we can pose at this point is why the current Web can be viewed as incomplete. In other worlds, why is the Semantic Web necessary. The reasons that justify this effort started to be depicted in the web scenarios in the Current Situation section. When the Web's current situation was shown through some conflictive scenarios, what was shown is that there are some tensions. The current evolution of the Web is overcoming its current design. These tension points can be characterized from various perspectives [Jasper01]:
All of these Web requirements depend in a fundamental way on the idea of semantics. This gives rise to a new integrative perspective along which the Web evolution may be viewed: the Web is evolving from containing information resources that have little or no explicit semantics to having a rich semantic infrastructure. Where, explicit is considered from a machine point of view.
There is no widespread agreement on exactly what the Semantic Web is, nor exactly what it is for. What poses the problems to define it is the word "semantic", as the word "web" and their connotations are actually almost the common use.
From the introductory cites at the beginning of this section, there is clear emphasis on the information content of the Web being machine usable and associated with more meaning. Here, “machine” refers to computers or computer programs that perform tasks on the Web. These programs are commonly referred to as software agents and are found in Web applications.
The simpler way of making machines aware of the semantics they should manage is the common way software is developed. Web-applications developers hardwire the knowledge into the software so that when the machine runs the software, it does the correct thing with the information.
In this situation, machines already use information on the Web. There are electronic broker agents that make use of the meaning associated with Web content words such as "price", "weight", "destination" and "airport", to name a few.
Armed with a built-in "understanding" of these terms, these so-called shopping agents automatically peruse the Web to find sites with the lowest price for a book or the lowest airfare between two given cities. Therefore, we still lack an adequate characterization of what distinguishes the future Semantic Web from what exists today.
Despite the current presence in the WWW of built-in semantics, the Semantic Web effort continues to make sense. Indeed, built-in semantics are the problem. The World Wide Web conforms a global communication medium where people and machines meet. If each one has their own built-in semantics, totally isolated from other ones, information flows but communication is impossible.
There are many attempts to make this communication space uniform enough to make possible global understanding. However, this is only viable at reduced scale. Therefore, many standardisation efforts have been done, are being done or are planned. Each one focuses on specific domains where consensus is possible.
People has the ability to grasp others terms semantics. They have a plethora of mechanisms to make themselves understandable and to understand what others say. The most important one is a huge amount of world knowledge. They can connect views and uses of words, or lets say standards. However, this is not easy and it is even worse when the scenario is the Web, there is an immense number of interlocutors from extremely different origins.
Here machines can help to manage these mappings but, first, we must help them understand what they are dealing with. The first step is to make semantics explicit using metadata. Semantic metadata is data about data that is machine-processable. Then, explicit semantics provide the anchor points that make possible semantic interconnections. To effectively build explicit and global semantics the different build-in semantics proper of each system or community should be interconnected.
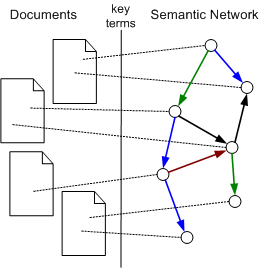
This is what the Semantic Web tries to do. It is based on relations between terms, where each term represent a concept. There are semantic relations between terms that capture their semantics. They can be followed when an unknown term is found. There are different types of relations that are used to carry meaning from known terms to unknown ones. From this carried meaning, a partial understanding of the new term can be build. This dynamic and declarative process can be based on a quite simple set of built-in semantic grounds. An example of a semantic network for a set of documents constructed from selected terms is shown Figure.
The semantic relations emerge from Semantic Web use in a completely free and distributed fashion. This conforms a dynamic agreement, usually partial, of common terms inside a community. Standards are difficult to achieve, and when more and more people is involved, it gets worse. They are so complicated to obtain because standards are a top-down efforts to be applied directly at the global scale. On the other hand, the Semantic Web encourages bottom-up efforts. Global constraints are reduced to the minimum, maintaining local ones, and are used only to focus on a global target.
Additionally, Semantic Web local structures, its documents, are kept simple. However, at the global scale, they build in conjunction a complex system. It provides easier evolvability and thus adaptation to new needs. However, this has a price, there can appear irresolvable questions, contradictions, etc. That is why, commonly, this strategy would not produce complete understanding, only partial.
All the a priori ideas presented in this section are arranged in the Semantic Web principles section. Then, these principles are put into practice in the Semantic Web architecture section.
The main intent of the Semantic Web is to give machines much better access to information resources so they can be information intermediaries in support of humans. Thanks to this semantic substrate, and according to the vision described in [Berners-Lee01], agents will be pervasive on the Web, carrying out a multitude of everyday tasks.
In order to carry out their required tasks, intelligent agents must communicate and understand meaning. They must advertise their capabilities, and recognize the capabilities of other agents. They must locate meaningful information resources on the Web and combine them in meaningful ways to perform tasks. They need to recognize, interpret, and respond to communication acts from other agents.
As mentioned before, when agents communicate with each other, there needs to be some way to ensure that the meaning of what one agent "says" is accurately conveyed to the other agent. The simplest and most common approach is to build-in the semantics. That is, just assume that all agents are using the same terms to mean the same things.
The assumption could be implicit and informal, or it could be an explicit agreement among all parties to commit to using the same terms in a pre-defined manner, i.e. a standard. This only works, however, when one has full control over what agents exist and what they might communicate.
In reality, agents need to interact in a much wider world, where it cannot be assumed that other agents will use the same terms, or if they do, it cannot be assumed that the terms will mean the same thing. Therefore, we need a way for an agent to discover what another agent means when it communicates. In order for this to happen, agents will need to publicly declare exactly what terms it is using and what they mean. This specification is commonly referred to as the agent's ontology. There is a great interdependence of agent technology and ontologies [Hendler01].
Here is where agents and the Semantic Web meet. Agent ontologies define the terms in metadata that describe the resources they work with. Terms in different ontologies are interconnected through the World Wide Web, the space where these agents operate. Therefore, when agents with different ontologies meet they can use connections between their respective ontologies to understand.
As has been presented in the previous section, the Semantic Web is a quest for a reduced set of commitments upon which understanding can be build. This connects directly with the ideas presented in the Automatic Semantics section. In the Semantic Web, machines deal with the representational dimension of semantics and thus they built a web of concepts connected by relations.
On the other hand, the World Wide Web offers to knowledge representation a promising workspace. Knowledge representation can expand from reduced and constrained application spaces to a huge and continuously evolving one. Moreover, there is the possibility that this complex space would allow knowledge representation techniques build more than isolated human-like intelligent behaviours.
What would emerge might be completely different to what traditionally knowledge representation, more concretely its application by Artificial Intelligence, has envisioned. For instance, there is the vision of an emerging global brain [Heylighen96, Heylighen97] as already mentioned in the Introduction section.
The driving force of the Semantic Web is to accommodate the previous objectives and to reuse the existent World Wide Web structure. Web reuse would facilitate a smooth transition from the previous web to the Semantic Web and increase the possibilities of its success.
Therefore, the WWW principles are also considered and some additional ones are included in order to fulfil the augmented requirements. These additional principles are detailed in the next subsections.
People, places, and things in the physical world will have online representations identified by Uniform Resource Identifiers which will facilitate effective integration, active participation and be conceptualised in the Semantic Web. URIs are the metadata anchor points to make semantics explicit.
Current Web is quite unrestricted; it sacrifices link integrity for scalability. This great lack of restrictions in the Web design make it fundamentally differed from traditional hypertext systems.
This is also a design principle of the Semantic Web ant thus it is also largely unrestricted. Therefore, there should be no fundamental constraint relating what is said, what it is said about, and where it is said. Anyone can say anything about anything. Consequently, it is not expected to have global consistency of all data.
Semantic Web provides tools that enable communities resolve ambiguities and clarify inconsistencies. The idea is to use conventions that can expand as human understanding expands.
The Semantic Web must permit distributed communities to work independently to increase the Web of understanding, adding new information without insisting that the old be modified. This approach allows the communities to resolve ambiguities and clarify inconsistencies over time while taking maximum advantage of the wealth of backgrounds and abilities reachable through the Web.
Therefore, the Semantic Web must be based on a facility that can expand as human understanding expands. This facility must be able to capture information that links independent representations of overlapping areas of knowledge.
The Semantic Web encourages the free flow of information but also it should guarantee group boundaries, i.e. restrictions to information access and thus privacy.
All statements found on the Web occur in some context. Applications need this context in order to determine the trustworthiness of the statements. The machinery of the Semantic Web does not assert that all statements found on the Web are "true", i.e. they are propositions that do hold in the world.
Truth, or more pragmatically, trustworthiness, is evaluated by and in the context of each application that processes the information found on the Web. Each application, or agent, states which other agents' statements it does trust. These relations of trust can be partially transitive and dynamically spread trust across the Web. Consequently, a parallel network of statements of trust is then build.
When an application founds a statement, its origin and a trust path to it can be retrieved. From this the statement trustworthiness in the application context can be derived. How this is planed to be done is detailed in the Architecture section.
The idea here is to make things simple now that plan for future complexity. The result would be then more than the sum of the parts. This can be summarised in the maxim: "Make the simple this simple, and the complex things possible" or as the Occam's razor principle: "Entities should not be multiplied unnecessarily".
In the Semantic Web it is translated into standardise nor more than is necessary. Construct a global interoperability framework with mapping rules defined over it. They are, in conjunction with the framework primitives, the only global agreement required.
To encompass the universe of network-accessible information, the Semantic Web must provide a way of exposing information from different systems. Application or community specific systems may use a variety of internal data models so this implies a requirement for some generic concept of data at a low level that is in common between each system.
Only when the common model is general can any community specific application be mapped onto the model. For instance, databases developed independently are difficult to unify. To solve this, data can be published using Semantic Web tools and then profit from mapping capabilities to achieve global interoperability.
One common approach can be seen both in the Web and in the Semantic Web. Indeed, it is the revolutionary idea inherited from the previous Web that is contributed to knowledge representation. It is the philosophy of the rhizome.
The rhizome serves as a metaphor for the multiplicity and infinite interconnectedness of all thought, life, culture, and language. Developed by the theorists Gilles Deleuze and Felix Guattari in their book "A Thousand Plateau's" [Deleuze87], from which there is an interesting quote:
"A rhizome ceaselessly establishes connections between semiotic chains, organizations of power, and circumstances relative to the arts, sciences, and social struggles. A semiotic chain is like a tuber agglomerating very diverse acts, not only linguistic, but also perceptive, mimetic, gestural, and cognitive: there is no language in itself, nor are there any linguistic universals, only a throng of dialects, patois, slangs, and specialized languages. There is no ideal speaker-listener, any more than there is a homogeneous linguistic community.... There is no mother tongue, only a power takeover by a dominant language within a political multiplicity. Language stabilizes around a parish, a bishopric, a capital. It forms a bulb. It evolves by subterranean stems and flows, along river valleys or train tracks; it spreads like a patch of oil. It is always possible to break a language down into internal structural elements, an undertaking not fundamentally different from a search for roots. There is always something genealogical about a tree. It is not a method for the people. A method of the rhizome type, on the contrary, can analyse language only by decentring it onto other dimensions and other registers. A language is never closed upon itself, except as a function of impotence."
Gilles Deleuze and Felix Guattari, "A Thousand Plateau's"
The Web provided the rhizome approach to the information level, where the rhizome approach stands for a hierarchy less, open and decentralised way of organisation. This approach, applied to information, has showed as the best suited in an Internet-connected world. Therefore, the novelty, and the challenge, is to apply it to the knowledge level, i.e. constructing a Web of interrelated ontologies.
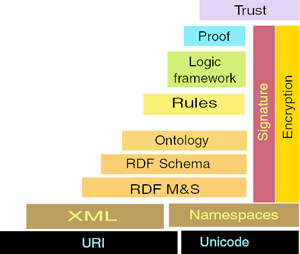
The previous ideas and principles to complete the Web are being put into practice under the guidance of the World Wide Web Consortium. To reduce the amount of standardisation required and increase reuse, the Semantic Web technologies have been arranged into a layer cake shown in Figure. The two base layers are inherited from the previous Web. The rest of the layers try to build the Semantic Web. The top one adds trust to complete a Semantic Web of trust.
The Semantic Web layers are arranged following an increasing level of complexity from bottom to top. Higher layers functionality depends on lower ones. This design approach facilitates scalability and encourages using the simpler tools for the purpose at hand. All the layers are detailed in the next subsections.
The two technologies that conform this layer are directly taken from the World Wide Web. URI provides global identifiers and UNICODE is a character-encoding standard that supports international characters.
In few words, this layer provides the global perspective, already present in the WWW, for the Semantic Web.
The Semantic Web should smoothly integrate with the Web. Therefore, it must be interwoven with Web documents. HTML is not enough to capture all that is going to be expressible in the Semantic Web. XML is a superset of HTML that can be used the serialisation syntax for the Semantic Web. XML was initially tried but more recently other possibilities have been developed. They are presented and compared in the next section.
Namespaces where added to XML to increase its modularisation and the reuse of XML vocabularies in conjunction with XML Schemas. They are also used in the Semantic Web for the same purpose.
The RDF Model and Syntax specification [Becket04] defines the building blocks to realise the Semantic Web. This is the first layer that was specifically developed for it. This specification defines the RDF graph model and the RDF abstract syntax.
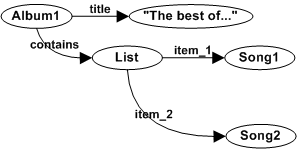
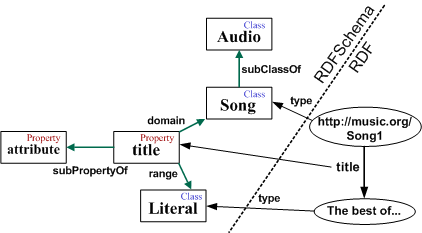
The RDF graph model defines a structure composed of nodes and directed edges between nodes. The structure of nodes and edges conform directed graphs that model the network of terms and relations between terms of the Semantic Web. The nodes and relations are called resources and are identified by URIs. Each node has its own URI and there are different types of relations that also have an URI, they are called properties. Figure shows and example of RDF graph model.
Particular edges are identified by the triad composed by the origin node, the property and the destination node. Triads are called triples ore RDF statements and they are the RDF abstract syntax. Graphs can be serialised as a set of triples, one for each edge in the graph. Both representations are equivalent so the graph model can be reconstructed from the set of triples.
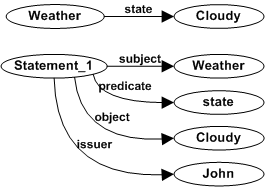
Triples can also be assigned an explicit identifier, i.e. an URI. This process is called reification. A new node is created that represents the triple and it is associated to three nodes for the three triple components. The origin node is associated using the "subject" property, the property with the "predicate" property and the destination node with the "object" property. Reification is useful to say things about RDF statements. For an example of use, see Figure.
Abstract triples are the common model to which diverse data structures can be mapped. For instance, relational tables can be translated to a set of triples. Notwithstanding, triples are abstract entities. They are realised for communication using serialisation syntaxes.
The XML syntax has already been introduced in the previous section, it facilitates integrating Semantic Web documents in the current HTML/XML web. The other possibilities are N-Triples and Notation 3 syntax, http://www.w3.org/DesignIssues/Notation3.html. The former is the nearest to the abstract form, a series of triples with subject, predicate and object identified by their URI. The latter uses many syntactic tricks to improve human readability and make serialisations more compact. It is the more human aware syntax and, like XML serialisation, it uses namespaces for modularisation.
Simple RDF provides the tools to construct semantic networks. They are a knowledge representation technology presented in the Semantic Networks section. Nonetheless, there is still a lack of many semantic network facilities not available with RDF.
There are no defined taxonomical relations. They are defined in the RDF Schema specification [Brickley04]. Taxonomical relations leverage RDF to a knowledge representation language with capabilities similar to semantic networks. This enables taxonomical reasoning about the resources and the properties that relate them.
RDF Schema specification provides some primitives from semantic networks to define metadata vocabularies. RDF Schemas implement metadata vocabularies in a modular way, like XML Schemas. Schema primitives are also similar to Object Orientation constructs they also evolved from the semantic networks tradition. The more relevant ones are detailed next and an example of their use is shown in Figure:
A first simile can be established at this stage. While HTML makes the Web behave like a global book when viewed at the worldwide level, RDF Model and Syntax plus RDF Schema make it behave like a global database.
Another simile with XML can also be clarifying. The basic RDF primitive, the graph, can be compared with the XML one, the tree. However, as an XML tree, an RDF graph is on its own basically unrestricted. Therefore, in order to capture the semantics of a particular domain, some primitives to build concrete "how things are connected" restrictions are necessary. RDF Schema provides these restriction-building primitives. It can be compared to XML Schema or DTDs, which provide building blocks to define restrictions about how XML elements and attributes are related.
Ontologies are necessary when the expressiveness achieved with semantic network-like tools is not enough. Metadata vocabularies defined by RDF Schemas can be considered simplified ontologies. The tools included in this layer rise the developed vocabularies to the category of ontologies. For a comparative with XML Schemas, see Table.
Ontologies, which were defined in the Knowledge Representation Ontology section, are specially suited to formalise domain specific knowledge. Once it is formalised, it can be easily interconnected with other formalisations. This facilitates the interoperability among independent communities and thus ontologies are one of the fundamental building blocks of the Semantic Web.
Description Logics are particularly suited for ontology creation. They were introduced in the corresponding Knowledge Representation subsection. The World Wide Web Consortium is currently developing a language for web ontologies, OWL [Dean04]. It is based on Description Logics and expressible in RDF so it integrates smoothly in the current Semantic Web initiative.
Description Logic makes possible to develop ontologies that are more expressible than RDF Schemas. Moreover, the particular computational properties of description logics reasoners make possible efficient classification and subsumption inferences.
When comparing ontologies and XML schemas directly we run the risk of trying to compare two incomparable things. Ontologies are domain models and XML schemas define document structures. Still, when applying ontologies to on-line information sources their relationship becomes closer. Then, ontologies provide a structure and vocabulary to describe the semantics of information contained in these documents. The purpose of XML schemas is prescribing the structure and valid content of documents, but, as a side effect, they also provide a shared vocabulary for the users of a specific XML application. Differences between ontologies and schema definitions:
|
The rules layer allows proof without full logic machinery. Similar rules are those used by the production systems presented in the corresponding Knowledge Representation subsection. They capture dynamic knowledge as a set of conditions that must be fulfilled in order to achieve the set of consequences of the rule.
The Semantic Web technology for this layer is the Semantic Web Rule Language (SWRL) [Horrocks04]. It is based on a previous initiative called Rule Modelling Language (RuleML) [Boley01]. As RuleML, SWRL covers the entire rule spectrum, from derivation and transformation rules to reaction rules. It can thus specify queries and inferences in Web ontologies, mappings between Web ontologies, and dynamic Web behaviours of workflows, services, and agents.
The purpose of this layer is to provide the features of FOL. First Order Logic was described as the most significant type of logic in the Logic types section. With FOL support, the Semantic Web has all the capabilities of logic available at a reasonable computation cost as shown in the Deduction section.
There are some initiatives in this layer. One of the first alternatives was RDFLogic [Berners-Lee03]. It provides some extensions to basic RDF to represent important FOL constructs, for instance the universal (∀) and existential (∃) quantifiers. These extensions are supported by the CWM [Berners-Lee05] inference engine. Another more recent initiative is SWRL FOL [Patel-Schneider04], an extension of the rule language SWRL in order to cope with FOL features.
The use of inference engines in the Semantic Web makes it open, contrary to computer programs that apply the black-box principle. An inference engine can be asked why it has arrived to a conclusion, i.e. it gives proofs of their conclusions.
There is also another important motivation for proofs. Inference engines problems are open questions that may require great or even infinite answer time. This is worse as the reasoning medium moves from simple taxonomical knowledge to full FOL. When possible, this problem can be reduced by providing reasoning engines pre-build demonstrations, proofs, that can be easily checked.
Therefore, the idea is to write down the proofs when the problem is faced and it is easier to solve as the reasoning context is more constrained. Further, proofs are used whenever the problem is newly faced as a clue that facilitates reasoning on a wider content.
Many inference engines specialised in particular subsets of logic have been presented so far. For instance:
This is the top layer of the Semantic Web architecture. Agents that want to work with the full-featured Semantic Web will be placed over it. They will conform the Web of Trust.
The trust layer makes use of all the Semantic Web layers below. However, they do not provide the required functionality to trustily bind statements with their responsible parts. This is achieved with some additional technologies that are shown in the right part of the Semantic Web stack Figure.
The used tools are digital signature and encryption. Thus, the trust web will make intensive use of Public Key Infrastructures. They are already present in the Web, for instance as digital certificates identifying parties that sign digital contracts. Notwithstanding, there is not a widespread use of them.
The premise is that Public Key Infrastructure is not of extended use because it is not a decentralised web structure. It is hierarchical and therefore rigid. What the Semantic Web might contribute here is a less constraining substrate of use. The web of trust is based on the graph structure of the Web. Moreover, it supports the dynamic construction of this graph. These features might enable the common use of Public Key Infrastructure in the future Web.
To conclude, the final Semantic Web picture contains reasoning engines complemented with digital signatures to construct trust-engines. Then, a Trust Web can be developed with rules about which signed assertions are trusted depending on signer.
The Semantic Web initiative started before the Web Services one, which was presented in the corresponding Web Technologies sub section. Web services are based on UDDI, WSDL, and SOAP technologies, which provide limited support in mechanising service recognition, configuration, comparison, combination and automated negotiation. Nonetheless, the idea behind Web Services is to realize complex workflows and business logics.
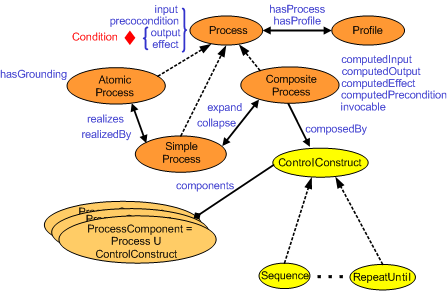
Therefore, some Semantic Web and Web Services initiatives are converging. There are development like OWL-S [Martin04] that employ Semantic Web technologies for services descriptions. OWL-S models web services as sets of semantically defined processes. Based on the described service semantics, mediation is applied based on data and process ontologies and the automatic translation of their concepts into each other. The top-level part of the OWL-S process ontology is shown in Figure.
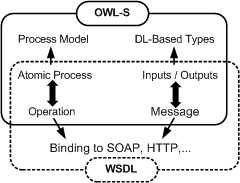
Technologies from both initiatives are complementary. Web services semantic description languages like DAML-S are situated as a higher-level layer above WSDL. UDDI, WSDL and SOAP continue to be used in semantic web services as the implementation machinery. DAML-S is used when advanced processing is needed to perform service recognition, configuration, comparison, combination and negotiation. A mapping between both is shown in Figure.