First of all, the premise that has guided this research work is to combine knowledge representation and web technologies in order to face digital rights management in a novel way. However, the intention is to take an approach that can be easily generalised and then applied to applications development in the Web. The first step of this approach is to analyse the application domain and construct a web ontology that captures the domain knowledge. This will be done to construct a knowledge model of the legal, commercial and management aspects of intellectual property creations and intellectual property rights. This knowledge model in the form of a web ontology constitutes the main contribution of this work. Therefore, the importance of this part justifies establishing a methodology that ensures, as much as possible, the productivity of the effort and the quality of the result.
The IEEE defines methodology as "a comprehensive, integrated series of techniques or methods creating a general systems theory of how a class of thought-intensive work ought to be performed". Actually, there is not a mature knowledge engineering methodology for ontology development [Fernández99b, Gómez04]. Some of them have been developed independently but they are tailored to particular ontology developments. It lacks a mature methodology that can be widely applied to guide future ontology developments. However, one of the existing methodologies can be highlighted because it is particularly interesting for ontology development in the Semantic Web. It is Methontology, a methodology for ontology development, which is detailed in the Methontology section. Methontology has guided the development of the copyright ontology that constitutes the fundamental contribution of this work. It is important to note that, in order to better integrate the Methontology results in the general discourse of this work, it has been used in a more narrative and less knowledge engineering oriented way.
Moreover, there are some parts of the contribution that complement the ontology. These parts extract the ontology full potential from a practical point of view. They will require software development methodologies and tools. For them, the Rational Unified Process [Kruchten98], the Unified Modelling Language [Booch99] and its evolution for agent-oriented development Agent UML [Huget04], are the chosen alternatives. However, these methodologies and tools should be adapted to fit the particularities of the knowledge-oriented approach. Particularly, the special features of the knowledge representation technologies used to exploit the knowledge layer.
Methontology [Fernández97] is a methodology for ontology construction. To improve its applicability it adopted some ideas from the more mature Software Engineering discipline. More concretely, its ontology development process is based on the activities identified in the IEEE standard for software development [Schultz97]. These activities are scheduled by the Methontology ontology life cycle that establishes the stages through which the ontology moves during its life time and the activities to be performed in each stage. Both parts of Methontology are detailed next.
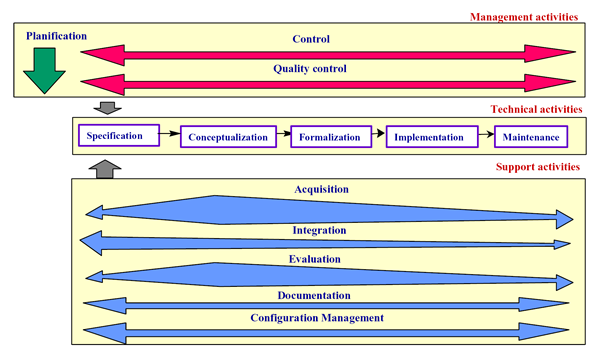
The process refers to which activities are performed when building ontologies. It identifies three categories of activities, as shown in Figure and detailed below:
The previous ontology development process identifies the activities to be performed. It does not say nothing about how the must be scheduled. This is determined by the other part of the methodology, the ontology life cycle, that establishes the stages through which the ontology moves during its life time and the activities to be performed in each stage.
The ontology life cycle schedules the ontology development activities detailed previously, although not all of them are currently considered by the Methontology life cycle. The life cycle is cyclic, based on evolving prototypes [Fernández00]. It allows an incremental development of the ontology that enables earlier validation and readjustment. Each cycle starts with the scheduling activity that identifies the tasks to be performed, their arrangement, their temporal extent and the resources they need. After that the development activities are engaged, starting with specification. Simultaneously, the management activities, control and quality assurance, and the support activities, knowledge acquisition, integration, evaluation, documentation and configuration management, are launched. They take place in parallel with the development activities.
Each cycle, the current prototype ontology moves along the development activities, from specification through conceptualisation, formalisation and implementation until maintenance, although it is not necessary to pass through all them. Eventually, the prototype might be mature enough for evaluation purposes and a new cycle can be engaged considering the conclusions from this evaluation. If a development cycle is completed, these are the steps that are performed:
As it has been said and it is shown in Figure, the activities in the management and support processes take place simultaneously with the development activities. The efforts applied to the support activities are not uniform along the life cycle. Knowledge acquisition, integration and evaluation are greater during ontology conceptualisation. This is due to most knowledge is acquired at the beginning of the development, ontologies are integrated at the conceptual level before implementation and it is better to accurately evaluate the conceptualisation as earlier as possible in order to avoid propagating errors.
It is important to note that all the relationships between activities detailed until this point are intra-dependencies, i.e. they are relationships between activities from the same ontology development process. Intra-dependencies define the ontology life cycle. Methontology considers also that activities for the development of an ontology may involve activities for other ontologies already built or under construction. These are called inter-dependencies and defined crossed life cycles of ontologies. They are necessary, for instance, because it is usually necessary to perform some changes before an ontology is integrated with the ontology currently under development.
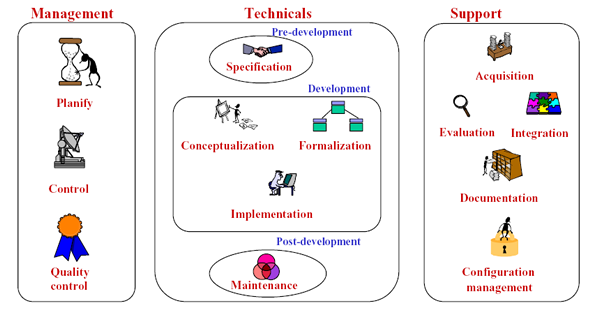
Now, there are more detailed descriptions of the activities scheduled by the Methontology ontology life cycle. They are organised in the management, development and support processes. The pre-development activities (environment and feasibility studies) and the post-development activity use are not detailed as they are not included in the current life cycle. Moreover, the maintenance activity is moved to the development process.
The management process activities are responsible for the project management issues [Rojas98].
Scheduling is the first activity of the ontology life cycle. The objective is to plan the main tasks to be done, how they will be arranged and the required resources, i.e. people, software and hardware.
Control is performed along the whole ontology life cycle in order to survey that there are not undesired deviations from the initial schedule.
Quality is responsible for checking that the quality of each methodology output (ontology, software and documentation) is assured.
The development process includes all the activities that produce the successive prototype refinement stages towards the desired ontology[Fernández99a]. The process starts with specification that produces an informal output that then evolves increasing its level of formality, as it passes through the different activities, towards the final computable model, which can be directly understood by the machine.
The specification establishes the ontology purpose and scope. Why the ontology is being built, what are the intended uses and end-users [Gómez98]. The specification can be informal, in natural language, or formal, e.g. using a set of competence questions [Uschold96].
The objective of this activity is to organize and structure the knowledge acquired during knowledge acquisition using external representations that are independent of the knowledge representation and implementation paradigms in which the ontology will be formalised and implemented next. An informally perceived view of a domain is converted into a semi-formal model using intermediate representations based on tabular and graph notations. These intermediate representations (concept, attribute, relation, axiom and rule) are valuable because they can be understood by domain experts and ontology developers. Therefore, they bridge the gap between people's domain perception and ontology implementation languages.
In order to build a consistent and complete conceptual model, the conceptualisation activity defines a set of tasks that should be executed in succession. These tasks increase, step by step, the complexity of the intermediate representations used to build the conceptual model. This way, it is easier to ensure a consistent and complete conceptual model:
The goal of this activity is to formalise the conceptual model. There are ontology development tools that automatically implement the conceptual model into several ontology languages using translators. Therefore, formalisation is not a mandatory activity.
This activity builds computable models using ontology implementation languages. There are many ontology languages and they do not have the same expressiveness nor do they reason the same way.
This activity updates and corrects the ontology if needed due to the necessities of the current development process or other processes that reuse this ontology in order to build other ontologies or applications.
The support activities are performed in parallel with the development-oriented activities.
First of all, the source knowledge must be captured using knowledge elicitation techniques [Uschold96]. The sources of knowledge are listed giving a description and specifying the elicitation techniques used in each case. The techniques used to extract knowledge from sources can be partially automatic by means of natural language analysis and machine learning techniques [Fernández99a, Gómez99].
The evaluation activity judges the developed ontologies, software and documentation against a frame of reference. Ontologies should be evaluated before they are used or reused. There are two kinds of evaluation, the technical one, which is carried out by developers, and users evaluation.
Ontology evaluation includes [Gómez95]:
The criteria for ontology evaluation are:
One method for ontology validation is Ontoclean [Guarino02], which is detailed in the next section.
The integration activity is needed if other ontologies are reused [Rojas98]. There are to options when an ontology is integrated in the current ontological framework. First, there is ontology alignment that consists in establishing different kinds of mapping between the ontologies, hence preserving the original ontologies. Second, ontology merging that produces a new ontology from the combination of the input ontologies.
Documentation details each completed stage and product.
Configuration management records ontologies, software and documentation versions in order to control changes [Rojas98].
As it has been pointed out in the Objectives chapter, the intention is to take profit from previous work in the RELs field. Almost all existing REL initiatives are based on XML. XML schemas are used to define REL grammars and they are the source from which the semantics they capture implicitly are going to be formalised and made explicit. A generic methodology for XML semantics reuse has been employed [García05c]. It is based on mapping from XML Schema constructs to the OWL ones that are semantically more appropriate. The previous mapping is complemented with a XML instance metadata to RDF instance metadata mapping. The latter makes possible to take existing XML metadata to the Semantic Web space. Both mappings are implemented by the ReDeFer project.
There are many attempts to make XML metadata semantics explicit. Usually, they translate it to Semantic Web languages that facilitate the forma-lisation. Some of them just model the XML tree using the RDF primitives [Klein02]. Others concentrate on modelling the knowledge implicit in XML languages definitions, i.e. DTDs or the XML Schemas, using web ontology lan-guages [Amann02, Cruz04]. Finally, there are attempts to encode XML semantics inte-grating RDF into XML documents [Lakshmanan03, Patel-Schneider02].
However, none of them facilitates an extensive transfer of XML metadata to the Semantic Web in a general and transparent way. Their main problem is that the XML Schema implicit semantics are not made explicit when XML metadata instantiating this schemas is mapped. Therefore, they do not take profit from the XML semantics and produce RDF metadata almost as semantics-blind as the original XML. Alternatively, they capture this semantics but they use additional ad-hoc semantic constructs that produce less transparent metadata.
Therefore, we have chosen the XML Semantics Reuse methodology that combines a XML Schema to web ontology mapping, called XSD2OWL, with a transparent mapping from XML to RDF, XML2RDF. The ontologies generated by XSD2OWL are used during the XML to RDF mapping in order to generate semantic metadata that makes XML Schema semantics explicit. Both steps are detailed in the next subsections.
As we have said, XML Schemas define some simple semantics. For instance, the substitutionGroup relations among elements and the extension/restriction base ones among complexTypes encode generalisation hierarchies. The XML Schema to OWL mapping is responsible for capturing the schema implicit semantics. This semantics are determined by the combination of XML Schema constructs. The mapping is based on translating this constructs to the OWL ones that best capture their semantics. These translations are detailed in Table and implemented by the XSD2OWL tool of the ReDeFer project.
In each row there is a mapping. If there is more than one line, there are indeed two mapping but very related. In the first column there are the XML constructs detailed using a XPath syntax [Simpson02]. The second column contains the OWL constructs to which the corresponding XML Schema construct is mapped.
In the case of elements and attributes, the possible OWL constructs are rdf:Property, owl:DatatypeProperty and owl:ObjectProperty. owl:DatatypeProperty is used for all attributes and those elements that have a simpleType as value, i.e. a string, integer, etc. value. owl:ObjectProperty is used for the elements that have a complexType as value. Finally, it is necessary to use rdf:Property for those elements that may have both a simpleType or complexType value, as this is possible with XML Schema but it is not recommended in OWL.
For the rest of the mappings that have more than one line in its second column, as they also have more than one line in its first column, there are more than one mapping per row and each line corresponds to one mapping. The third column points out informally in which respect the XML Schema and OWL construct for the given mapping are related.
XSD2OWL translations for the XML Schema constructs and shared semantics with OWL constructs
| XML Schema | OWL | Shared informal semantics |
| element|attribute | rdf:Property owl:DatatypeProperty owl:ObjectProperty |
Named relation between nodes or nodes and values |
| element@substitutionGroup | rdfs:subPropertyOf | Relation can appear in place of a more general one |
| element@type | rdfs:range | The relation range kind |
| complexType|group| attributeGroup |
owl:Class | Relations and contextual restrictions package |
| complexType//element | owl:Restriction | Contextualised restriction of a relation |
| extension@base| restriction@base |
rdfs:subClassOf | Package concretises the base package |
| @maxOccurs @minOccurs |
owl:maxCardinality owl:minCardinality |
Restrict the number of occurrences of a relation |
| sequence choice |
owl:intersectionOf owl:unionOf |
Combination of relations in a context |
The XSD2OWL mapping is quite transparent and captures a great part XML Schema semantics. The same names used for XML constructs are used for OWL ones, although in the new namespace defined for the ontology. Therefore, XSD and OWL constructs names are identical; this usually produces uppercase-named OWL properties because the corresponding element name is uppercase, although this is not the usual convention in OWL. Moreover, it also possible to have anonymous XML constructs, concretely complexTypes defined implicitly inside a element definition. In this case, the OWL constructs are named with element name concatenated with the "Range" word.
The only caveats are the implicit order conveyed by sequence and the exclusivity of choice. For the first problem, owl:intersectionOf does not retain its operands order, there is no clear solution that retains the great level of transparency that has been achieved. The use of RDF Lists might impose order but introduces ad-hoc constructs not present in the original metadata. Moreover, as it has been demonstrated in practise, the elements' ordering does not contribute much from a semantic point of view. For the second problem, owl:unionOf is an inclusive union, the solution is to use the disjointness OWL construct, owl:disjointWith, between all union operands in order to make it exclusive.
For the predefined simpleTypes that are included in the current OWL specification, i.e. datatypes like xsd:string or xsd:boolean, the mapping is direct. For the user defined simpleTypes, as there is not a standard method for custom datatypes in OWL, all user defined simpleTypes are mapped to xsd:string in order to keep their lexical values intact. Although this causes a loose of semantic information in the resulting OWL ontology, it is still possible to validate instance XML metadata against the original XML Schema prior to mapping it to RDF. Consequently, this lack in the OWL ontology can be overcome and the final RDF metadata is consistent with the XML Schema user defined simpleTypes.
Finally, some post-mapping adjustments may be necessary in order to solve name collisions between an OWL class and a RDF property. This is due to the fact that XML has independent name domains for complexTypes and elements while OWL has a unique name domain for all constructs. Moreover, the resulting OWL ontology is OWL-Full because the XSD2OWL translator has employed rdf:Property for those elements that have both data-type and object-type ranges.
Once XML Schemas are available as mapped OWL ontologies, it is also possible to map the XML metadata that instantiates them. The intention is to produce RDF metadata as transparently as possible. Therefore, a structure-mapping approach has been selected [Klein02] and implemented by the XML2RDF tool of the ReDeFer project.
It is also possible to take a model-mapping approach [Tous05]. XML model-mapping is based on representing the XML information set using semantic tools. This approach is better when XML metadata is semantically exploited for concrete purposes. However, when the objective is semantic metadata that can be easily integrated, it is better to take a more transparent approach.
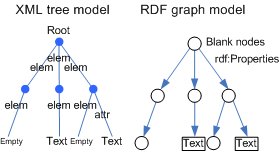
Transparency is achieved in structure-mapping models because they only try to represent the XML metadata structure, i.e. a tree, using RDF. The RDF model is based on the graph so it is easy to model a tree using it. Moreover, we do not need to worry about the semantics loose produced by structure-mapping. We have formalised the underlying semantics into the corresponding ontologies and we will attach them to RDF metadata using the instantiation relation rdf:type.
The structure-mapping is based on translating XML metadata instances to RDF ones that instantiate the corresponding constructs in OWL. The more basic translation is between relation instances, from xsd:elements and xsd:attributes to rdf:Properties. Concretely, owl:ObjectProperties for node to node relations and owl:DatatypeProperties for node to values relations. However, in some cases, it would be necessary to use rdf:Properties for xsd:elements that have both data type and object type values.
Values are kept during the translation as simple types and RDF blank nodes are introduced in the RDF model in order to serve as source and destination for properties. They will remain blank for the moment until they are enriched with semantic information, as it is shown in Figure.
The resulting RDF graph model contains all that we can obtain from the XML tree. It is already semantically enriched thanks to the rdf:type relation that connects each RDF properties to the owl:ObjectProperty or owl:DatatypeProperty it instantiates. It can be enriched further if the blank nodes are related to the owl:Class that defines the package of properties and associated restrictions they contain, i.e. the corresponding xsd:complexType. This semantic decoration of the graph is formalised using rdf:type relations from blank nodes to the corresponding OWL classes.
At this point we have obtained a semantics-enabled representation of the input metadata. The instantiation relations can now be used to apply OWL semantics to metadata. Therefore, the semantics derived from further enrichments of the ontologies, e.g. integration links between different ontologies or semantic rules, are automatically propagated to instance metadata thanks to inference.
These mappings have been validated in different ways. First, OWL validators have beem used in order to check the resulting OWL ontologies. Moreover, the two mappings have been tested in conjunction. Testing XML instances have been mapped to RDF, guided by the corresponding OWL ontologies from the used XML Schemas, and then back to XML. Then, the original and derived XML instances have been compared using their canonical version in order to correct mapping problems.